之前在运营开发规范化一文中提过工作中涉及一个运营平台。曾有段时间我一直吐槽该平台的代码实现有多烂,各种功能的逻辑有多“野蛮”,应尽快改造,但也许“worse is better”,我的吐槽只能仅仅是吐槽而已了。
最近该平台终于频繁出问题了。原因是上线了一个新功能---生产系统的模块之间每发生一次模块调用,就会调用该运营平台的API上报一次数据,该API的逻辑是将上报的数据存入Redis中。API由PHP实现,服务器以Nginx + PHP-FPM的方式处理API调用请求。当生产系统的业务量增大,模块直接的调用次数频率增大直接导致API调用的频率增大, 加上该平台所在服务器各种cron任务等的影响,导致在某些时候,PHP-FPM子进程数量飙升,跑满CPU,并且PHP-FPM子进程的数目持续不降(原因不明)。这样导致一方面用户无法访问该平台---服务器响应502(Nginx接受请求,但PHP-FPM无法处理该请求),另一方面更多的数据上报API调用无法完成,造成大量数据丢失和误告警。 用户怨声载道,领导也很头疼,要求尽快搞定该问题,但迟迟没人挑起这个活。
为了开个头,上上个周末的一天我绘制了两张对比图(如下所示),尝试给出建议方案。
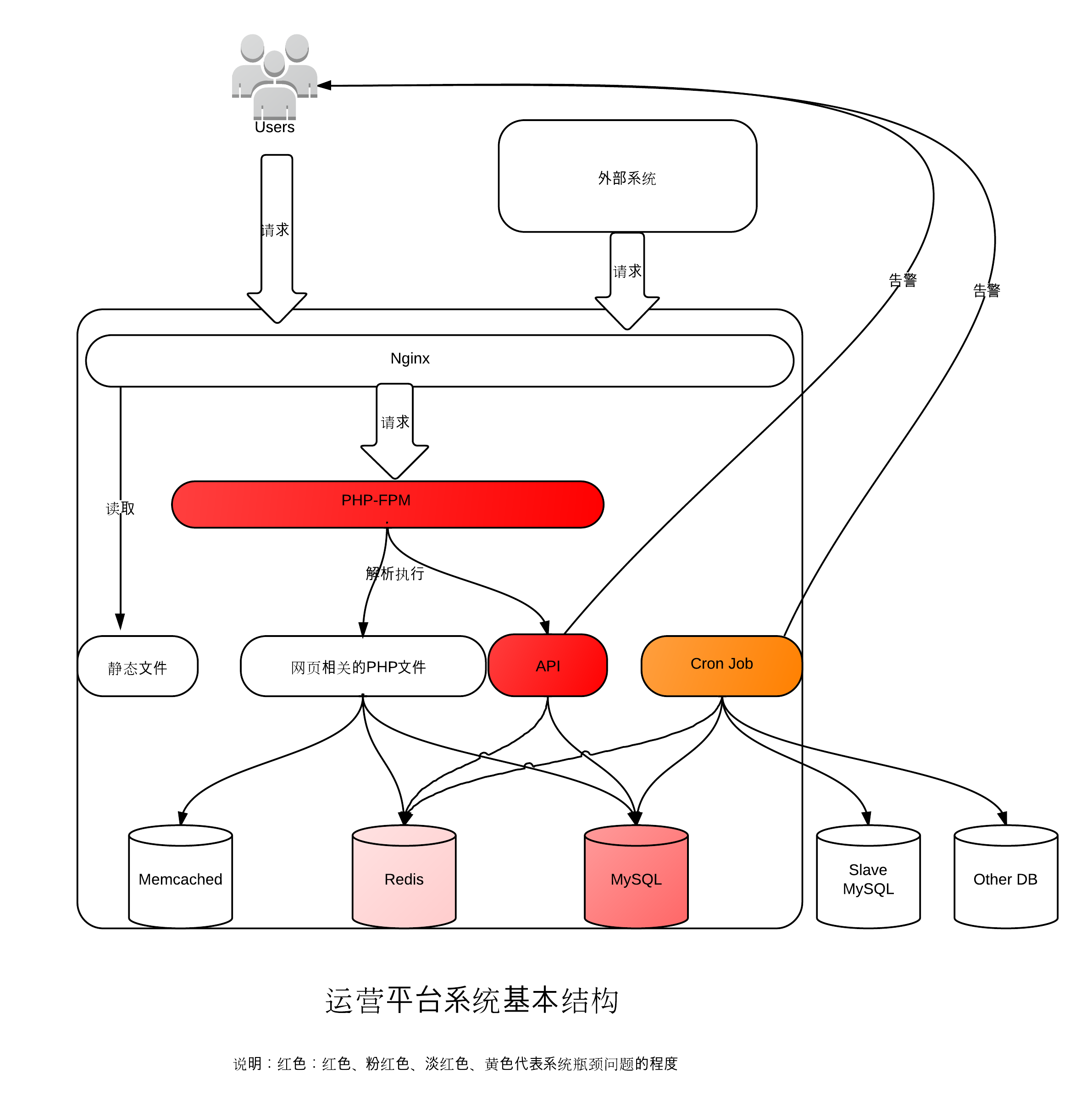
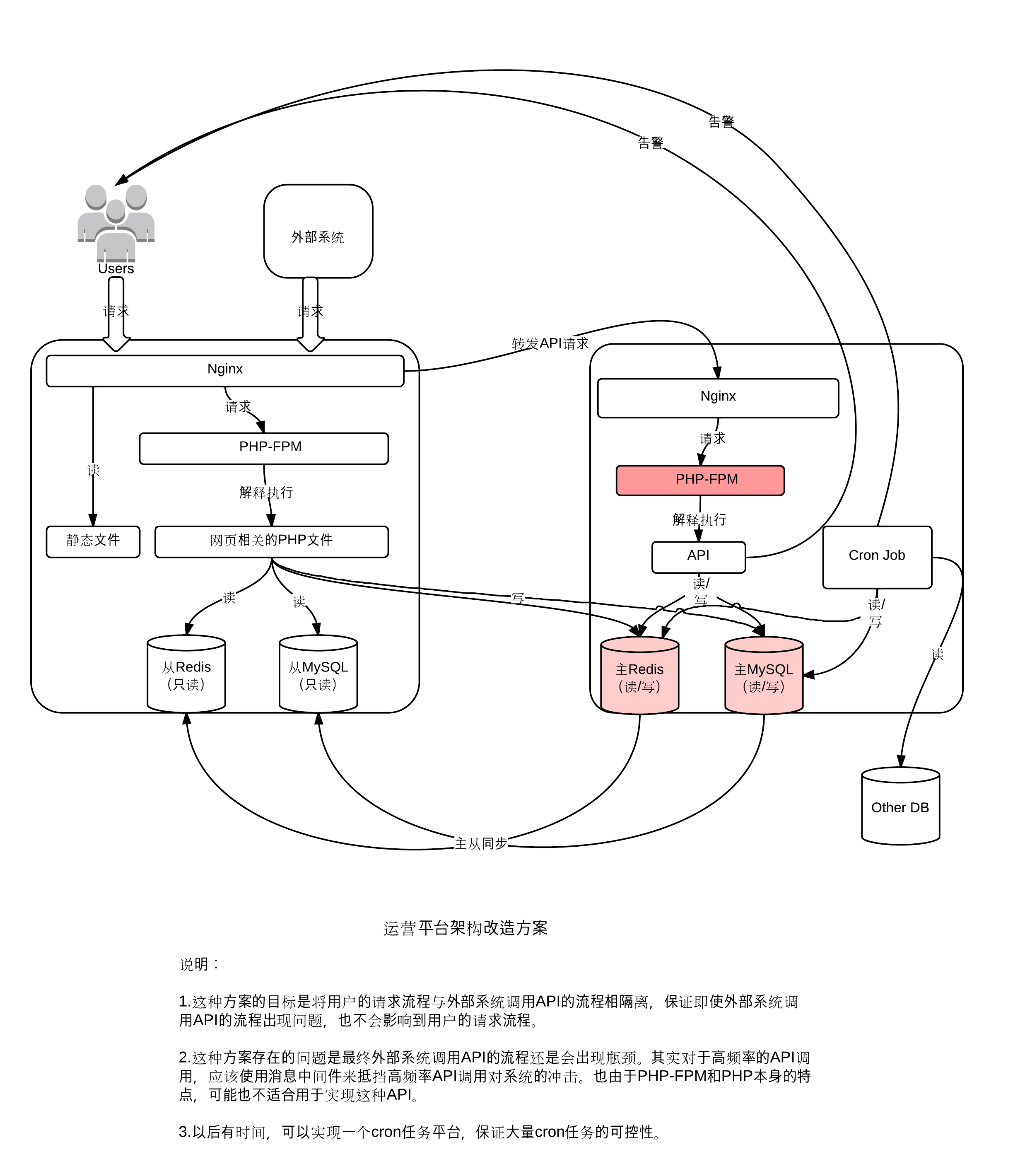
这种方案的时间成本较低,无需改动对外API,也无需大量修改代码。