Reactor 官方文档(简译)
1. 起步
1.1 Reactor 简介
Reactor 是为 JVM 准备的一个完全非阻塞的反应式编程基础组件,支持高效的需求管理(以管理“反压”的形式),直接与 Java 8 的函数式 API 集成,尤其是 CompletableFuture、Stream 以及 Duration,提供可组合的异步序列 API - Flux(适用于 N 个元素的序列)和 Mono(适用于 0 或 1个元素的序列)--- 并且全面地(extensively)实现了 反应式流(Reative Streams) 规范。
借助 reactor-netty 项目,Reactor 也支持进程间的非阻塞通信,适用于微服务架构。reactor-netty 为 HTTP(包括 Websockets)、TCP 以及 UDP 提供支持反压的网络引擎,完全支持反应式编码解码。
1.2 理解 BOM
Reactor 3 开始采用 BOM (Bill of Materials,物料清单)发布模型(自 reactor-core 3.0.4 开始,使用 Aluminium(铝)版本序列),一个版本包含一组相关组件的版本,这些版本组件之间兼容性非常好,允许这些组件采用不同的版本命名方式。
BOM 发布模型本身也是版本化的,以一个代号后接一个修饰词来命名一个版本序列。如下是一个示例列表:
Aluminium-RELEASE
Californium-BUILD-SNAPSHOT
Aluminium-SR1
Bismuth-RELEASE
Californium-SR32代号等价于常规的 大版本号.小版本号 形式,通常以字母升序方式取自 元素周期表。
按照时间顺序,修饰词分别为如下几个:
- BUILD-SNAPSHOT:为开发测试构建的版本。
- M1 .. N:里程碑版本或者开发者预览版本。
- RELEASE:一个代号系列中的首个 GA(General Availability 通用)发行版。
- SR1 .. N:一个代号系列中的后续 GA 发行版 - 相当于一个补丁版本。(SR 代表 “Service Release”(服务版本))
1.3 如何获取 Reactor
1.3.1 以 Maven 管理依赖包
Maven 原生支持 BOM 模型概念。首先,在你的 pom.xml 文件添加如下代码片段来引入 BOM:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-bom</artifactId>
<version>Bismuth-RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>如果顶部标签(dependencyManagement)已经存在,则只添加上面该标签的内部内容。
接下来,将依赖包添加到项目中,和一般依赖包一样,不过没有 <version>,如下所示:
<dependencies>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-core</artifactId>
</dependency>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>1.3.2 以 Gradle 管理依赖包
Gradle 核心并不支持 Maven BOM,不过可以借助 Spring 的 gradle-dependency-management 插件。
首先,应用插件,如下所示:
plugins {
id "io.spring.dependency-management" version "1.0.6.RELEASE"
}然后使用它来引入 BOM,如下所示:
dependencyManagement {
imports {
mavenBom "io.projectreactor:reactor-bom:Bismuth-RELEASE"
}
}最后将依赖添加到项目中,无需指定版本号,如下所示:
dependencies {
compile 'io.projectreactor:reactor-core'
}2. 反应式编程简介
Reactor 是反应式编程范式的一个实现。反应式编程的定义归纳起来,如下所示:
反应式编程是一个异步编程范式,关注数据流和变化的传播。这意味着通过被采用编程语言可以轻松地表达静态(比如 数组)或动态(比如 事件发射器)数据流。 --- https://en.wikipedia.org/wiki/Reactive_programming
反应式编程方向的首个重要工作是:微软在 .NET 生态体系中创建了反应式扩展(Rx)库,然后 RxJava 在 JVM 上实现了反应式编程。时光飞逝,经 Reative Streams 的大力推进,Java 社区终于出现了反应式编程标准,该规范定义了一组接口以及 JVM 上反应式编程库之间的交互规则。Java 9 标准库已将这组接口集成到 Flow 类(译注:见https://docs.oracle.com/javase/9/docs/api/java/util/concurrent/Flow.html)中。
反应式编程范式在面向对象语言中通常表现为一个观察者设计模式的扩展。你也可以将主流的反应式流模式(reactive streams pattern)和大家熟知的迭代器设计模式做对比,所有这些库中都存在对标于 Iterable - Iterator 的概念(译注:比如 发布者-消费者)。主要差别在于:迭代器是基于 pull 方式,反应式流则基于 push 方式。
使用迭代器是一个命令式编程的模式,即使如何访问数据(accessing values)完全是 Iterable 的职责,但实际上,何时访问序列中的下一个(next())值取决于开发者的选择。在反应式流中,上述 Iterable - Iterator 对的等价物为 Publisher - Subscriber。不过,在出现新的数据/事件时,由 Publisher 通知 Subscriber,这个“推”特性也是实现反应式的关键之处。并且,在被推送的值上应用哪些操作是声明式表达而不是命令式表达的:程序员表达的是计算逻辑而不是描述精确的控制流。
除了“推”的特性,反应式流也良好地定义了如何处理错误和结束流。一个 Publisher 可以向它的 Subscriber 推送新的值(通过调用订阅者的 onNext 方法),也可以推送错误(调用 onError 方法)或结束(调用 onComplete方法)信号。错误和结束信号都可以终结事件序列。简而言之,如下所示:
onNext x 0..N [onError | onComplete]这个方式非常灵活。这个模式支持“没有值”、“一个值”或“n个值”(包括值无限的序列,比如时钟的持续滴答事件)的各种使用场景。
但是,起初,我们为什么需要这样一个异步的反应式的编程库?
2.1 阻塞即是资源浪费
现代的软件应用,并发用户量非常巨大,即使现代硬件的处理能力一直在提升,软件的性能仍旧是一个关键问题。
宽泛来讲,提升一个程序的性能,有两种方式:
- 并行化 使用更多的线程和更多的硬件资源。
- 对于当前的硬件资源,寻求更高效的使用方式。
通常,Java 开发者会使用阻塞性的代码编写程序,这种代码编写方式容易触及性能瓶颈,然后引入更多的线程来运行相似的阻塞性代码。但是,这种资源利用的扩展方式很快就会引发竞态(contention)和并发的问题。
更糟糕的是,阻塞就意味着浪费资源。如果你稍加分析,就会发现一旦程序牵涉一些等待延迟(尤其是 I/0 操作,比如等待一个数据库请求或者一个网络调用),资源就会被浪费,因为此时线程(可能是大量线程)是空闲的,等待着数据。
因此,并行化方式并非银弹。为了压榨出硬件的全部能力,并行化是必要的,但并行化的代码理解(reason about)起来也非常复杂,实际威力也会因为资源浪费而大打折扣。
2.2 异步可以解决问题吗?
前面提到的第二种方式 - 寻求更高效的使用方式 - 是资源浪费问题的一个解决方案。通过编写异步非阻塞的代码,在发生阻塞等待时,切换执行另一个活跃任务,活跃任务使用的是相同的底层资源,然后在异步处理过程结束后再切回到当前进程来执行。
但是我们如何编写在 JVM 上异步执行的代码? Java 提供了两种异步编程模型:
- 回调:异步方法没有返回值,但接受一个额外的
callback(回调)参数(一个 lambda 表达式或匿名类),在得到异步处理结果时会调用这个回调。一个众所周知的例子是 Swing 的EventListener派生类。 - Future:这种异步方法在调用时会即刻返回一个
Future<T>。这个异步过程会计算出一个T类型的值,不过需要通过Future对象来访问。计算出来的值不能立即可用,可以对Future对象进行探询直到值计算出来。例如:ExecutorService运行Callable<T>任务就是提供Future对象来获取异步结果。
那么这两种技术方案就足够好了吗?在很多使用场景下并不理想,这两种方式都有局限。
多个回调难以组合使用,容易导致代码难以阅读和维护(就是所谓的“回调地狱”)。
来看一个例子:在界面上为用户显示他最喜爱的5个物件,如果用户还没有任何喜欢的物件,则给出建议物件。这个逻辑涉及3个服务(第一个服务提供物件 ID,第二个服务获取物件的详细信息,第三个服务提供建议物件的详细信息),如下所示:
回调地域的示例
userService.getFavorites(userId, new Callback<List<String>>() { // 1
public void onSuccess(List<String> list) { // 2
if (list.isEmpty()) { // 3
suggestionService.getSuggestions(new Callback<List<Favorite>>() {
public void onSuccess(List<Favorite> list) { // 4
UiUtils.submitOnUiThread(() -> { // 5
list.stream()
.limit(5)
.forEach(uiList::show); // 6
})
}
public void onError(Throwable error) { // 7
UiUtils.errorPopup(error);
}
});
} else {
list.stream() // 8
.limit(5)
.forEach(favId -> favoriteService.getDetails(favId, // 9
new Callback<Favorite>() {
public void onSuccess(Favorite details) {
UiUtils.submitOnUiThread(() -> uiList.show(details));
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
}
));
}
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
})- 基于回调的服务:
Callback接口定义了两个方法,异步处理成功时调用其中的onSuccess,异步处理发生错误时调用onError。 - 第一个服务以其结果 - 喜爱物件的 ID 列表 - 调用回调方法。
- 如果列表为空,则必须转到
suggestionService来处理。 suggestionService向第二个回调传递一个List<Favorite>列表。- 对于 UI 渲染,必须让消费数据的代码运行在 UI 的线程中。
- 这里我们使用了 Java 8 的
Stream将建议物件的数量限制为5个,然后在 UI 中渲染成一个图形化列表。 - 在每个回调层级,我们都以相同的方式处理错误:在弹出框中显示错误信息。
- 回到 喜爱物件 ID 列表的层级。如果
userService服务返回一个不为空的 ID 列表,则转到favoriteService去获取带详细信息的Favorite对象。因为只需要5个喜爱物件,所以先使用流式处理将 ID 数量限制为 5 个。 - 再一次,使用一个回调。这一次我们获取到完整的
Favorite对象,并在 UI 线程中将其在 UI 上渲染出来。
看看有多少代码,理解起来也有点困难,其中也有一些重复的代码片段。再来看看使用 Reactor 如何来实现这段逻辑:
和回调实现方式等价的 Reactor 实现
userService.getFavorite(userId) // 1
.flatMap(favoriteService::getDetails) // 2
.switchIfEmpty(suggestionService.getSuggestions()) // 3
.take(5) // 4
.publishOn(UiUtils.uiThreadScheduler()) // 5
.subscribe(uiList::show, UiUtils::errorPopup); // 6- 开启一个喜爱物件 ID 的流。
- 异步地将 ID 转换成带详细信息的
Favorite对象(flatMap)。至此我们得到一个Favorite对象流。 - 如果
Favorite流为空,则切换到备选处理方式suggestionService。 - 我们只关注产出流中的前(最多)5个元素。
- 最后,在 UI 线程中处理每份数据。
- 真正触发流的处理:描述了如何处理最终的数据(显示为一个 UI 列表),以及在发生错误时如何处理(显示一个弹出框)。
如果希望确保在 800ms 以内获取到喜爱物件 ID 列表,如果超时,则从缓存中获取数据,如何实现?基于回调的代码实现,这是一个复杂的任务。使用 Reactor,只需在操作链中添加一个 timeout 算子就能轻松搞定,如下所示:
超时回退处理的 Reactor 代码示例
userService.getFavorites(userId)
.timeout(Duration.ofMillis(800)) // 1
.onErrorResume(cacheService.cachedFavoritesFor(userId)) // 2
.flatMap(favoriteService::getDetails)
.switchIfEmpty(suggestionService.getSuggestions())
.take(5)
.publishOn(UiUtils.uiThreadScheduler())
.subscribe(uiList::show, UiUtils::errorPopup);- 如果前置处理超过 800ms 还没输出任何事件,则下发一个错误。
- 在收到错误事件时,回退到调用
cacheService。 - 操作链的余下部分和前一个例子类似。
使用 Future 对象相比回调更好一点,不过组合使用起来也不太方便,尽管 Java 8 引入 CompletableFuture 改善了这一问题。将多个 Future 对象组织在一起,可行但并不容易。另外,Future 还有其它问题:
- 容易碰到另一个阻塞的情况:调用
Future对象的get()方法。 - 不支持惰性计算。
- 对多个值的处理和高级错误处理缺乏支持。
来看看另一个例子:先获取一个 ID 列表,然后根据 ID 获取一个名字以及获取一个统计数值,再将名字和统计数值组合起来使用,这几个步骤都必须是异步的。如下示例以一组 CompletableFuture 来实现这个逻辑:
CompletableFuture<List<String>> ids = ifhIds(); // 1
CompletableFuture<List<String>> results = ids.thenComposeAsync(l -> { // 2
Stream<CompletableFuture<String>> zip =
l.stream().map(i -> { // 3
CompletableFuture<String> nameTask = ifhName(i); // 4
CompletableFuture<Integer> statTask = ifhStat(i); // 5
return nameTask.thenCombineAsync(statTask, (name, stat) -> "Name " + name + " has stats " + stat); // 6
});
List<CompletableFuture<String>> combinationList = zip.collect(Collectors.toList()); // 7
CompletableFuture<String>[] combinationArray = combinationList.toArray(new CompletableFuture[combinationList.size()]);
CompletableFuture<Void> allDone = CompletableFuture.allOf(combinationArray); // 8
return allDone.thenApply(v -> combinationList.stream()
.map(CompletableFuture::join) // 9
.collect(Collectors.toList()));
});
List<String> results = result.join(); // 10
assertThat(results).contains(
"Name NameJoe has stats 103",
"Name NameBart has stats 104",
"Name NameHenry has stats 105",
"Name NameNicole has stats 106",
"Name NameABSLAJNFOAJNFOANFANSF has stats 121");- 一开始获得一个
Future结果 - 为后续处理提供一个id列表。 - 一旦获得
id列表就可以开始进一步的异步处理。 - 逐个处理列表中的元素。
- 异步获取关联的名字。
- 异步获取关联的统计数值。
- 组合两个异步结果。
- 至此我们得到一个
Future对象列表,表示所有的组合任务。 - 将
Future对象数组传给CompletableFuture.allOf方法,这个方法会输出一个Future对象,当Future对象数组代表的异步任务都完成时,这个Future对象代表的异步任务也就完成了。 - 此处的特殊之处在于:在(
allOf返回的)CompletableFuture<Void>对象表示的异步任务结束时,遍历Future对象列表(combinationList),使用join()方法(此次不会阻塞,因为allOf会确保所有异步任务都已完成)获取收集异步任务结果。
10. 触发执行整个异步处理流水线(调用 join() 方法),然而等着异步处理完成并返回一个结果列表,就可以进行断言判断了。
Reactor 自带了很多组合算子,可以简化这个处理过程的实现,如下所示:
Flux<String> ids = ifhrIds(); // 1
Flux<String> combinations =
ids.flatMap(id -> { // 2
Mono<String> nameTask = ifhrName(id); // 3
Mono<Integer> statTask = ifhrStat(id); // 4
return nameTask.zipWith(statTask, // 5
(name, stat) -> "Name " + name + " has stats " + stat);
});
Mono<List<String>> result = combinations.collectList(); // 6
List<String> results = result.block(); // 7
assertThat(results).containsExactly( // 8
"Name NameJoe has stats 103",
"Name NameBart has stats 104",
"Name NameHenry has stats 105",
"Name NameNicole has stats 106",
"Name NameABSLAJNFOAJNFOANFANSF has stats 121"
);- 这次,一开始我们得到一个异步提供的字符串序列(
ids)(一个Flux<String>对象)。 - 对于序列中的每个元素,异步处理两次(在
flatMap的 lambda 参数值中)。 - 获取关联的名字。
- 获取关联的统计值。
- 异步组合两个值
- 在异步处理的结果可用时,将它们聚合到一个
List对象中。 - 在实际项目中,我们通常会继续异步处理
Flux,比如:异步组合使用它或者直接订阅它。最可能的是,返回这个Mono类型的result。因为这里只是个测试,所以使用了 block,等待处理结束,直接返回值的聚合列表。 - 对结果进行断言判断。
使用回调和 Future 对象的问题是类似的,反应式编程以 发布者(Publisher)- 订阅者(Subscriber) 解决了这些问题。
2.3 从命令式到反应式编程
反应式编程库,比如 Reactor,目标是解决 JVM 上“经典”异步处理方式的弊端,同时也专注于提供以下几个方面的特性:
- 可组合性 和 代码可读性
- 将数据视作一个流,并提供丰富的算子来操作流
- 在订阅(subscriber)之前不会实际做任何事情
- 反压 或者说 消费者通知生产者流速过高的能力
- 与并发无关(concurrency-agnostic)的高阶(high level)抽象,适用性强(high value)(译注:并发无关是指这种抽象对于并发非并发的场景都适用)
3. Reactor 核心特性
Reactor 项目的主要成果是 reactor-core - 一个遵循反应式流规范并支持 Java 8 的反应式编程库。
Reactor 引入 2 个可组合的反应式类型(实现了 Publisher 接口并且提供丰富的算子): Flux 和 Mono。一个 Flux 对象代表包含 0 到 N 个元素的反应式序列,Mono 对象代表单值或空(0或1个元素)的结果。
3.1 Flux - 0-N 个值的异步序列
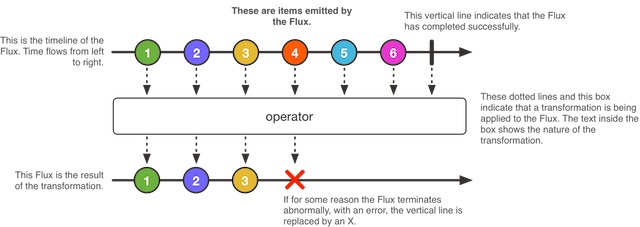
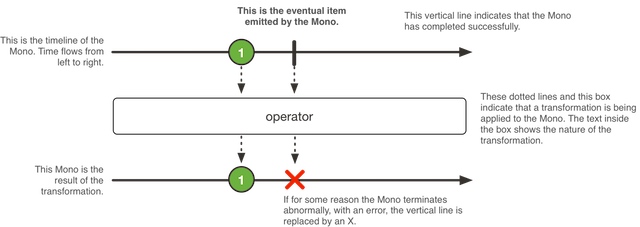
3.2 Mono - 包含 0 或 1 个值的异步结果
3.3 创建一个 Flux 或 Mono 并进行订阅的一些简单方法
Flux 和 Mono 的类中包含大量的工厂方法,上手使用 Reactor 最简单的方式是从中选择一个用起来。
例如,创建一个 String 序列,可以逐个列举出这些字符串,或者将这些字符串放到一个集合中,然后基于这个集合创建一个 Flux,如下所示:
Flux<String> seq1 = Flux.just("foo", "bar", "foobar");
List<String> iterable = Arrays.asList("foo", "bar", "foobar");
Flux<String> seq2 = Flux.fromIterable(iterable);其它一些工厂方法的使用示例如下所示:
Mono<String> noData = Mono.empty();
Mono<String> data = Mono.just("foo");
Flux<Integer> numbersFromFiveToSeven = Flux.range(5, 3);对于订阅操作,Flux 和 Mono 借助了 Java 8 的 lambda 表达式。有大量 .subscribe() 的重载方法/变种方法(variants)可选选择使用,使用 lambda 表达式来实现回调的不同组合,如下所示是这些方法的签名:
Flux 中基于 lambda 表达式的订阅方法变种
subscribe();
subscribe(Consumer<? super T> consumer);
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer);
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer,
Runnable completeConsumer);
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer,
Runnable completeConsumer,
Consumer<? super Subscription> subscriptionConsumer);这些订阅方法都会返回一个订阅操作的引用,当不再需要更多的数据时,可以使用这个引用来取消订阅。一旦取消,数据源就应该停止产出数据,并清理使用的所有资源。这一 “取消并清理” 行为在 Reactor 中以通用的
Disposable接口来表现。
3.3.1 lambda 表达式的替代方案:BaseSubscriber
Flux 和 Mono 提供了一个相比上面那么订阅方法更通用的 subscribe 方法,其参数是一个完整的 Subscriber 实例,而不是根据几个 lambda 表达式组合出一个 Subscriber 实例。为了方便实现这样的一个 Subscriber,Reactor 提供了一个名为 BaseSubscriber 的可扩展的抽象类。
下面来实现一个,我们将其命名为 SampleSubscriber。如下示例演示了如何将其应用到一个 Flux 序列上:
SampleSubscriber<Integer> ss = new SampleSubscriber<Integer>();
Flux<Integer> ints = Flux.range(1, 4);
//
ints.subscribe(i -> System.out.println(i),
error -> System.err.println("Error " + error),
() -> {System.out.println("Done");},
s -> s.request(10));
//
ints.subscribe(ss);如下示例演示了 SampleSubscriber 继承自 BaseSubscriber 的一个最简化实现:
package io.projectreactor.samples;
import org.reactivestreams.Subscription;
import reactor.core.publisher.BaseSubscriber;
public class SampleSubscriber<T> extends BaseSubscriber<T> {
public void hookOnSubscribe(Subscription subscription) {
System.out.println("Subscribed");
request(1);
}
public void hookOnNext(T value) {
System.out.println(value);
request(1);
}
}BaseSubscriber 还提供了一个 requestUnbounded() 方法来切换到无限消费模式(相当于 request(Long.MAX_VALUES)),另外也提供了一个 cancel() 方法。
除了 hookOnSubscribe 和 hookOnNext,BaseSubscriber 还提供了其他钩子方法(方法体为空,提供继承重写):hookOnComplete、hookOnError、hookOnCancel 以及 hookFinally(当事件/消息序列(流)终止时,一定会调用该方法,调用时会传入一个 SignalType 类型参数表示终止的类型)。
3.3.2 关于反压和调整请求量的方式
在 Reactor 中实现反压,是通过向上游算子发送一个 请求(request)来逐级传播消费者的压力,直到数据源。当前请求的总量有时又称为当前的“需求量” 或者 “待满足(pending)的请求量”。需求量的上限是 Long.MAX_VALUE,表示一个无限量的请求(意思是“尽快产出数据“ - 反压也就失效了)。
最终的订阅者在订阅之前会发出首个请求,订阅所有消息/数据最直接的方式是即刻触发一个无限量(Long.MAX_VALUE)的请求:
subscribe()以及大部分基于 lambda 表达式的变种方法(除了那个接受Consumer<Subscription>类型参数的方法)block()、blockFirst()和blockLast()- 调用
toIterable()或toStream()进行遍历
对首个请求进行定制的最简单方式是以一个 BaseSubscriber 派生类实例来 subscribe,派生类重写 BaseSubscriber 的 hookOnSubscribe 方法,如下所示:
Flux.range(1, 10)
.doOnRequest(r -> System.out.println("request of " + r))
.subscribe(new BaseSubscriber<Integer>() {
@Override
public void hookOnSubscribe(Subscription subscription) {
request(1);
}
@Override
public void hookOnNext(Integer integer) {
System.out.println("Cancelling after having received " + integer);
cancel();
}
});上面这个代码片段输出如下内容:
request of 1
Cancelling after having received 1改变下游需求量的算子
谨记:订阅时指定的需求量,上游操作链中的每个算子都可以对其作出调整。一个典型案例是 buffer(N) 算子:如果它收到一个 request(2) 请求,它会理解为2个缓冲区的请求量。因为缓冲区需要 N 个元素才认为是满的,所以 buffer 算子将请求量调整成了 2 x N。
你也许也注意到某些算子存在这样的变种 - 接受一个名为 prefetch 的 int 类型参数。这是另外一类修改下游请求量的算子。这类算子(比如 flatMap)通常是处理内部序列(inner sequences),从每个进入的元素派生出一个 Publisher。
预取(prefetch)是调整内部序列请求量的一个方式。如果未指定,多数这类算子会以 32 为初始需求量。
这类算子通常也会实现一个填补优化方案:算子一旦看到 25% 的预取请求量已完成,就会向上游再发起 25% 的请求量。这是一个启发式优化,如此这类算子就可以主动地为即将到来的请求量做好准备。
最后,再介绍一对直接用于调整请求量的算子:limitRate 和 limitRequest。
limitRate(N) 把下游的请求量拆分成多个更小量的请求向上游传播。例如,一个 100 的请求传到算子 limitRate(10),则会变成 10 次请求,一次请求 10,传播到上游。注意:limitRate 实际上以这种形式实现了前面提到的填补优化方案。
这个算子有一个变种,允许开发者调整预取填补量(即算子变种的 lowTide 参数):limitRate(highTide, lowTide)。lowTide 参数设定为 0 时,会导致严格限制一次请求 highTide 个,而不是经填补策略进一步调整过的一次请求量。
此外,limitRequest(N) 则是限制了下游最大的需求总量。它会累加请求量直到 N。如果一次请求没有让需求总量超过 N,则这次请求会完整地传播到上游(译注:意思是如果一次请求让需求总量超过了 N,这次请求的请求量会被裁剪)。如果数据源发出的数据总量达到了限制的总量,limitRequest 则认为这个序列可以结束了,向下游发送一个 onComplete 信号,并取消数据源。
3.4 动态地(programmatically)创建一个序列
3.4.1 同步的 generate
动态创建一个 Flux 最简单的方式是借助 generate 方法,该方法接受一个生成器函数。
这一方式可以实现同步的且一个接一个地下发数据,这意味着接收方(sink)是一个 SynchronousSink,其 next() 方法在一次回调方法调用中最多只能调用一次。可以在其后再调用 error(Throwable) 或 complete(),视你的需求而定。
generate 方法变种的这个应该是最有用的:允许保持一个状态,在调用接收方的 next 方法时可以基于这个状态来决定下发什么数据。那么这个生成器函数就成了一个 BiFunction<S, SynchronousSink<T>, S> 实例,其中 <S> 即是状态对象的类型。对于初始状态,可以提供一个 Supplier<S> 来获取,这样生成器函数每轮调用都会返回一个新的状态。
例如,可以使用一个 int 实例作为状态:
// 基于状态的 generate 方法使用示例
Flux<String> flux = Flux.generate(
() -> 0, // 1
(state, sink) -> {
sink.next("3 x " + state + " = " + 3*state); // 2
if (state == 10) sink.complete(); // 3
return state + 1; // 4
});- 以 0 作为初始状态。
- 基于状态(state)决定下发什么消息/数据。
- 基于状态决定何时可以停止流/序列。
- 返回一个新状态,下次调用时可以使用(除非在这次调用时已经终止序列)。
也可以使用一个 <S> 类型的可变对象。比如,上面的示例可以使用一个 AtomicLong 实例作为状态来重写,每轮调用都会改变它的值:
Flux<String> flux = Flux.generate(
AtomicLong::new,
(state, sink) -> {
long i = state.getAndIncrement();
sink.next("3 x " + i + " = " + 3*i);
if (i == 10) sink.complete();
return state;
});如果状态对象在序列终止时需要清理一些资源,则应该使用
generate(Supplier<S>, BiFunction, Consumer<S>)变种方法来清理最后的状态实例。
如下示例使用的 generate 方法接受一个 Consumer 类型参数:
Flux<String> flux = Flux.generate(
AtomicLong::new,
(state, sink) -> {
long i = state.getAndIncrement();
sink.next("3 x " + i + " = " + 3*i);
if (i == 10) sink.complete();
return state;
}, (state) -> System.out.println("state: " + state));3.4.2 异步多线程的 create
create 是动态创建一个 Flux 的更高级的方式,适用于每轮下发多个数据,甚至是从多个线程中下发数据。
这个方法会向回调方法传入一个 FluxSink 实例参数,在回调方法体中可以调用这个参数的 next、error 和 complete 方法。与 generate 不同,它没有基于状态的变种方法。另外,回调方法中,可以多线程地触发事件(trigger multi-threaded events)。
create非常适用于将一个已有的 API (比如:一个基于监听器的异步 API)桥接到反应式上下文中。
create并不会自动并行化执行你的代码,也不会让处理过程自动变成异步的,即使它可以配合异步 API 使用。如果在create的 lambda 表达式中发生阻塞,就会存在死锁或者其它副作用的风险。即使借助subscribeOn,也要当心createlambda 表达式中长时间的阻塞(比如无限循环调用sink.next(t))锁住流水线处理: (译注:异步的)数据请求可能根本得不到执行,因为(译注:线程池只有一个线程)同一个线程一直被无限循环占用着。使用subscribeOn(Scheduler, false)变种方法:requestOnSeparateThread = false将使用Scheduler的线程来执行create方法的回调,在原始的线程中执行request,从而让数据仍然可以流动起来。(译注:此处逻辑有点绕,也可能是因为 subscribeOn 方法本身语义就不太直观)。
假设我们要使用一个基于监听器的 API,它按块处理数据,提供两类事件:(1)来了一块数据,(2)处理可以结束了(终止事件),如下 MyEventListener 接口定义所示:
interface MyEventListener<T> {
void onDataChunk(List<T> chunk);
void processComplete();
}我们使用 create 将这个 API 桥接到一个 Flux<T> 实例上:
Flux<String> bridge = Flux.create(sink -> {
myEventProcessor.register( // 4
new MyEventListener<String>() { // 1
public void onDataChunk(List<String> chunk) {
for(String s : chunk) {
sink.next(s); // 2
}
}
public void processComplete() {
sink.complete(); // 3
}
}
);
});- 桥接到
MyEventListenerAPI - 数据块中每个元素都成了
Flux中的元素。 processComplete事件转换成了onComplete事件。- 所有这些逻辑都是在
myEventProcessor执行时异步完成的。
此外,因为 create 可以桥接异步 API,并管理反压,通过指定一个 OverflowStrategy 策略,可以调整如何智能地处理反压:
IGNORE完全忽略下游的反压请求。这一策略在下游的队列满时(when queues get full downstream)会导致IllegalStateException异常抛出。ERROR在下游处理不过来时会下发(onError)一个IllegalStateException异常消息。DROP如果下游还没准备好接收当前事件,则直接丢弃。BUFFER(默认策略)如果下游处理不过来,则将所有事件放入缓冲区。(缓冲区大小无限制,所以可能会导致内存溢出OutOfMemoryError)
Mono也有一个create生成器方法。Mono 的 create 方法传入回调的MonoSink参数不允许下发多个消息,在第一个消息之后它会丢弃所有的消息。
3.4.3 异步单线程的 push
push 的功能介于 generate 和 create 之间,适用于处理来自单个生产者的事件。push 也可以是异步的,也可以使用 create 支持的超限策略来管理反压,然而,同时(at a time)只能有一个生产线程调用 next。
Flux<String> bridge = Flux.push(sink -> {
myEventProcessor.register(
new SingleThreadEventListener<String>() { // 1
public void onDataChunk(List<String> chunk) {
for (String s: chunk) {
sink.next(s); // 2
}
}
public void processComplete() {
sink.complete(); // 3
}
public void processError(Throwable e) {
sink.error(e); // 4
}
}
);
});- 桥接到
SingleThreadEventListener的 API。 - 在单个监听器线程中使用
next向下游(sink - 接收方)推送事件。 complete事件也是由同一个监听器线程发出的。error事件也是由同一个监听器线程发出的。
推/拉 混合模型
多数 Reactor 算子,比如 create,都遵从 推/拉(push/pull) 混合模型。这意味着尽管大部分的处理过程都是异步的(暗指“推”的方式),也存在小部分逻辑是 拉(pull)方式:数据请求。
消费者从数据源拉取数据,意指:数据源在消费者首次请求后才会发出数据,然后只有要数据就会推送给消费者,不过数据量不会超过消费者请求的量。
push() 和 create() 都可以配置(set up)一个 onRequest 事件消费者来管理请求量,并且确保仅当存在已发起的请求,数据才会推送给下游。
Flux<String> bridge = Flux.create(sink -> {
myMessageProcessor.register(
new MyMessageListener<String>() {
public void onMessage(List<String> messages) {
for (String s: messages) {
sink.next(s); // 3
}
}
}
);
sink.onRequest(n -> {
List<String> messages = myMessageProcessor.getHistory(n); // 1
for (String s: messages) {
sink.next(s); // 2
}
});
});译者注:上面这个示例有点问题,实际并不存在这样一个 create 方法,并且 sink.onRequest 实际代表一个无限量(n = Long.MAX_VALUE)的请求。
- 在请求发起后,拉取消息。
- 如果即刻有消息了,则推送给下游。
- 后续异步到达的消息也会推送给下游。
3.5 多线程 和 调度器 (Threading and Schedulers)
Reactor,与 RxJava 类似,可以认为是并发无关的,也就是说,Reactor 并不强制使用并发(a concurrency
model),而是,让开发者按需决定是否使用并发。然而,Reactor 也提供一些功能方便开启并发。
获取到一个 Flux 或 Mono 处理流,并不意味着它在一个专用(dedicated)的线程(Thread) 中运行。相反,多数算子也是运行在前一个算子运行的线程中。除非特意指定,首个(topmost)算子(数据源)就运行在执行 subscribe() 方法调用的线程中。如下示例在一个新建线程中运行一个 Mono 处理流。
public static void main(String[] args) {
final Mono<String> mono = Mono.just("Hello "); // 1
new Thread(() -> mono
.map(msg -> msg + "thread ")
.subscribe(v -> // 2
System.out.println(v + Thread.currentThread().getName()) // 3
)
).join();
}Mono<String>是在主(main)线程中装配的(assembled)。- 然而, 订阅操作发生在
Thread-0线程中。 - 因而,
map和onNext的回调(译注:onNext的回调即 subscribe 方法传入的 lambda 表达式)实际上也是在Thread-0上执行。
上述的代码会输出如下内容:
hello thread Thread-0Reactor 中,运行模型以及实际的运行过程发生在什么地方由使用什么 Scheduler 决定。Scheduler 类似于 ExecutorService,负有调度职责,但具备一个专用的抽象,功能更强大,充当一个时钟的角色,可用的实现更多。
Schedulers 类提供了一些静态方法来访问这些运行上下文:
- 当前线程(
Schedulers.immediate())。 - 单个可复用的线程(
Schedulers.single())。注意:这个方法会为所有调用方(译注:调用 Schedulers.single())复用同一个线程,指导Scheduler销毁(disposed)。如果期望每次调用返回一个专用线程,则应该使用Schedulers.newSingle()。 - 一个弹性的线程池(
Schedulers.elastic())。这个 Scheduler 会按需创建新的工作者线程池(worker pool),并复用空闲的工作者线程池。如果工作者线程池空闲时间太长(默认 60s)则会被销毁。对于 I/O 阻塞工作而言这是一个好选择。Schedulers.elastic()可以简便地为阻塞处理过程提供独立的线程(its own thread),这样阻塞操作就不会占用(tie up)其他资源。详情请参考 如何包装一个同步阻塞的调用? - 固定数量工作者的(译注:我暂时的理解 - 工作者(worker)也是一个线程池)一个池,专门为并行处理工作做过调优(Schedulers.parallel())。它会创建和 CPU 核心数量相同的工作者。
此外,也可以使用 Schedulers.fromExecutorService(ExecutorService) 基于已有的 ExecutorService 创建一个 Scheduler。(也可以基于一个 Executor 来创建,但不建议这么干(译注:因为 Executor 不能销毁释放))
也可以使用 newXXX 这类方法创建各种调度器(scheduler)类型的全新实例。例如,使用 Schedulers.newElastic(yourScheduleName) 创建一个名为 yourScheduleName 的全新的弹性调度器(elastic scheduler)。
elastic调度器用于兼容处理不可避免的历史遗留的阻塞性代码,但single和parallel调度器不行,因而,如果在single或parallel调度器上使用 Reactor 的阻塞性 API(block()、blockFirst()、blockLast(),或者进行toIterable()或toStream()迭代),会导致抛出IllegalStateException异常。如果自定义调度器所创建的线程实例实现了
NonBlocking标记性接口(marker interface),那么这个调度器也可以被标记为”仅适用于非阻塞性使用(non blocking only)“。
某些算子默认会从 Schedulers 选择一个特定的调度器来使用(通常也支持选择其他的)。例如,调用工厂方法 Flux.interval(Duration.ofMills(300)) 会生成一个 Flux<Long> 实例 - 每 300 ms 输出一个滴答事件。这个方法底层实现默认使用 Schedulers.parallel()。如下代码行演示了如何将调度器修改成类似于 Schedulers.single() 的调度器新实例:
Flux.interval(Duration.ofMillis(300), Schedulers.newSingle("test"));Reactor 提供了两种方式来切换反应式链中的执行上下文(或者说 调度器):publishOn 和 subscribeOn。两者都是接受一个 Scheduler 类型参数并将执行上下文切换到这个调度器。不过,链中 publishOn 所处的位置很关键,而 subscribeOn 处于哪个位置都无所谓。要理解这个差别的原因,得先理解 订阅之前实际什么都没有发生。
Reactor,串接算子,就是将很多 Flux 和 Mono 的实现一个套一个,逐层封装。一旦订阅,就创建了一个 Subscriber 对象链,沿链回溯即可找到第一个发布者。这些实现细节是隐藏在接口背后,开发者可见的是最外层的那个 Flux(或 Mono)以及 Subscription(译注:Reactor 中 Subscription 是一个接口类型,是 Subscriber 接口中 onSubscribe 方法参数的类型 - public void onSubscribe(Subscription s),用于向生产者请求数据 或者 取消订阅),但这些算子特定的链中消费者是幕后功臣。
有了上面这些认知,现在我们可以进一步了解 publishOn 和 subscribeOn 这两个算子:
3.5.1 publishOn 方法
publishOn 和其他算子的用法一样,用在订阅链的中间环节,接收来自上游的信号,然后向下游重放这些信号,不过下发事件回调(onEvent、onError、onComplete)是在关联 Scheduler 的一个工作者上执行的。因此,这个算子会影响后续算子在哪执行(直到订阅链上又串接了另一个 publishOn):
- 将执行上下文切换到
Scheduler选择的一个线程上 - 根据规范(as per the specification),
onNext是按时序依次调用下发事件的,所以是占用一个线程(译注:这句不太理解,onNext happen in sequence, so this uses up a single thread) - 除非算子工作在一个特定的
Scheduler上(译注:某些算子的内部实现决定了这一点),publishOn之后的算子都是在同一个线程上执行
Scheduler s = Schedulers.newParallel("parallel-scheduler", 4); // 1
final Flux<String> flux = Flux
.range(1, 2)
.map(i -> 10 + i) // 2
.publishOn(s) // 3
.map(i -> "value " + i); // 4
new Thread(() -> flux.subscribe(System.out::println));- 创建一个新的
Scheduler,内含 4 个线程 - 第一个
map运行在 <第5步> 的匿名线程上 publishOn将整个序列的后续处理切换到从 <第1步> 选出的线程上- 第二个
map运行在上面说的从 <第1步> 选出的线程上 - 这个匿名线程是 订阅 操作发生的地方。打印语句发生在
publishOn切换的最新执行上下文上
3.5.2 subscribeOn 方法
subscribeOn 在构造反向链时应用于订阅处理过程(译注:所谓构造反向链时,是指调用 subscribe 方法时)。因此,无论你将 subscribeOn 放在算子链的何处,它始终会影响源头下发数据的执行上下文。然而,这并不会影响 publishOn 之后算子调用的行为,它们仍然会切换到 publishOn 指定的执行上下文。
- 从订阅操作发生时整个算子链所在的线程切换到新的线程
- 从指定
Scheduler中选择一个线程
只有链中最早的
subscribeOn调用会发生实际作用。
Scheduler s = Schedulers.newParallel("parallel-scheduler", 4); // 1
final Flux<String> flux = Flux
.range(1, 2)
.map(i -> 10 + i) // 2
.subscribeOn(s) // 3
.map(i -> "value " + i); // 4
new Thread(() -> flux.subscribe(System.out::println)); // 5 - 创建一个新的
Scheduler,内含 4 个线程 - 第一个
map运行在这 4 个线程中的某个线程上 - ...因为
subscribeOn将整个序列处理链从订阅操作发生时的执行上下文(第5步)切换到了新的上下文 - 第二个
map和第一个map运行在同一个线程上 - 这个匿名线程是 订阅操作 一开始发生的地方的,但是
subscribeOn即刻将上下文切换到调度器4个线程中的一个上
4. 高级特性和概念
4.1 使用 ConnectableFlux 将消息广播到多个订阅者
以后有空再翻译
4.2 3种分批处理方式
以后有空再翻译
4.3 使用 ParallelFlux 并行化处理
如今多核架构已是下里巴人,相应地,轻松实现并行化工作的工具手段很关键。Reactor 提供了一个特殊类型 - ParallelFlux - 帮助实现并行化处理。ParallelFlux 提供的算子是为并行化工作优化过的。
对任意 Flux 实例调用 parallel()算子就能得到一个 ParallelFlux 实例。这个方法本身并不能实现并行化工作,而是将工作负载拆分到多个“轨道”(默认“轨道”数量等于 CPU 核数)[1]。
为了告知产出的 ParallelFlux 实例每个“轨道”在哪执行(以及如何并行执行“轨道”),则必须使用 runOn(Scheduler)。注意:对于并行工作,推荐使用一个专用调度器 - Schedulers.parallel()。
对比如下两个示例,第一个示例的代码如下所示:
Flux.range(1, 10)
.parallel(2) // 1
.subscribe(i -> System.out.println(Thread.currentThread().getName() + " -> " + i));- 这里强制指定了“轨道”数量,而不依赖于 CPU 核数。
第二个示例的代码如下所示:
Flux.range(1, 10)
.parallel(2)
.runOn(Schedulers.parallel())
.subscribe(i -> System.out.println(Thread.currentThread().getName() + " -> " + i));第一个示例输出如下内容:
main -> 1
main -> 2
main -> 3
main -> 4
main -> 5
main -> 6
main -> 7
main -> 8
main -> 9
main -> 10第二个示例正确地在两个线程上实现了并行化,输入如下所示:
parallel-1 -> 1
parallel-2 -> 2
parallel-1 -> 3
parallel-2 -> 4
parallel-1 -> 5
parallel-2 -> 6
parallel-1 -> 7
parallel-1 -> 9
parallel-2 -> 8
parallel-2 -> 10如果数据序列[2]已经在并行化处理,而你又想将其转回一个 “常规的” Flux 实例,然后串行执行算子链余下的部分,则可以使用 ParallelFlux 的 sequential() 方法。
注意:如果直接使用一个 Subscriber 类型参数而不是 lambda 表达式来调用 subscribe 方法,那么内部实现会隐式地调用 sequential() 方法。
由此也要注意:subscribe(Subscriber<T>) 会合并所有数据“轨道”,而 subscribe(Consumer<T>) 是运行所有的数据“轨道”。如果以 lambda 表达式调用 subscribe 方法,那么每个 lambda 表达式都会被复制成多个实例(数量等于“轨道”数量)去执行[3]。
译注:这里的“轨道”其实不太直白。在实现上,
ParallelFlux会将最后subscribe的 onNext 回调按并行度(默认等于 CPU 核数 N)复制成 N 个,那么最终调用 ParallelFlux 的 N 个 Subscriber,从 ParallelFlux 实例到一个 Subscriber 的数据流路径可以理解为一个“轨道”,ParallelFlux 在接收到上游消息后按照 round-robin 方式选择一个 Subscriber 调用其onNext下发消息,但onNext是运行在什么线程上,是由 runOn 算子决定的,如果不使用 runOn 算子,那么所有 Subscriber 的onNext方法调用都是同步运行在主线程上的。↩译注:原文中用了多个词来表达相近的意思:sequence(序列)、stream(流)、flow(流),阅读时可以相互替代理解。此外,还有 event(事件)、data(数据)、message(消息),在当前上下文中,可以看成是等价的。↩
译注:这话写得真蠢。详细解释见脚注 1。↩