今年3月底毕业,入职腾讯做运营开发,至今6个月有余。入职之时组内仅有1个运营开发的同事,到目前已扩充到5人,加3个实习生。
入职之时的运营开发过程是这样的:
- 在办公机器(Windows)上编写代码,功能测试通过后,
- ssh远程连接到生产服务器(Linux),vim打开一个新文件,复制办公机器上的代码,粘贴到vim中,保存,
- 打开浏览器测试上线的功能/效果是否正确,若不正确,
- 直接在生产服务器上编辑代码文件,直到达到需要的功能效果,
- 再从生产服务器上将修改后的代码复制粘贴到办公机器(也许不会有这一步,之后所有的修改都直接在生产服务器上操作)。
这个过程存在如下问题:
- 代码没有版本控制
- 没有与生产服务器一致的测试环境
- 代码部署过程繁琐
- 办公开发机器上代码很可能比生产服务器上代码还旧
- 上面4点都会导致混乱
除此之外,当团队从1人扩充到多人后,不可避免地会遇到协作的问题,解决代码开发协作问题一般涉及如下几方面:
- 使用代码版本控制
- 规定版本控制的工作流
- 编码规范
- 项目/代码文档
- 定期code review
为了解决上述问题,我陆续地做了如下工作:
搭建Gitlab服务器、测试服务器
个人认为开发工作规范化的第一点就是版本控制,基于版本控制可以完成很多自动化的任务。
平时个人的代码、文档都通过Git版本控制存放在Github上,所以选择Gitlab来自建类Github平台,服务器的搭建过程见: 搭建测试服务器(源码编译方式)。
测试服务器和Gitlab服务器是同一台机器,在Git服务器端某个版本库的hooks目录下添加post-receive hook脚本,当有代码提交时,触发执行该脚本,脚本会将该版本库各个分支的代码更新到特定目录中, 然后以每个目录为root添加Nginx虚拟主机配置。这样每次代码提交后,就可以直接打开浏览器查看效果了。hook脚本代码见:post-receive.py。
该hook脚本的实现比较暴力---任何代码提交都会检查签出所有分支代码。
目前为止,Gitlab平台已得到较好的使用,但由于所要开发的运营平台涉及到一些监控数据API问题,很难有效地使用测试服务器,所以测试服务器一直没有正式使用起来。
选择一种Git工作流
若是单个使用Git,那么Git的工作流基本上就是:git status,git add xxx, git commit -m "xxx",git pull,git push origin master。
当涉及多人协作时,为了减少手动合并代码的工作量以及尽可能避免污染Git远程服务器版本信息,Git工作流就要复杂一些。
我们的Git工作流如图所示:
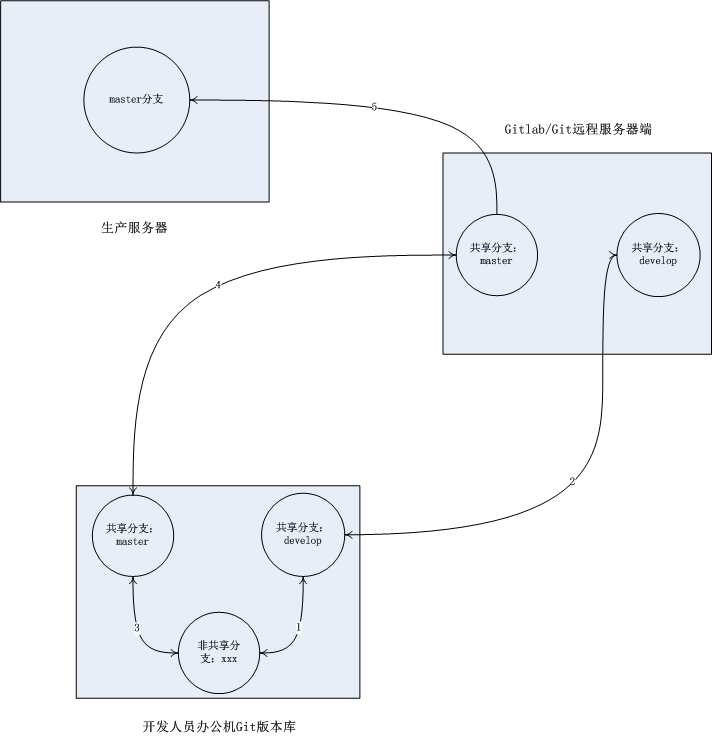
Git远程服务器端和办公机端版本库都保持两个共享分支:master和develop。master分支是稳定分支,其最新代码与生产服务器上的代码一致。develop是测试分支。
开发人员开发新功能或fix bug时,先在本地机器从master分支创建一个非共享分支xxx,在xxx分支中编写代码;需要在测试服务器测试代码时,将xxx分支合并入develop分支,将develop分支push到远程服务器; 经测试后,确定需要上线生产服务器,则将xxx分支合并入master分支,并push远程服务器,生产服务器从master分支pull代码进行部署。
这种工作流能避免“先提交的代码后上线”而导致的版本回滚问题。
生产服务器上的代码迁入版本控制
这项工作虽然工作量不大,却值得一提。因为不能影响正常的服务,也不能导致任何文件的丢失损坏,所以应该慎之又慎。
我选择周末在公司完成该工作,过程如下:
- 在Gitlab上新建一个版本库,如xxx;
- 将生产服务器上的代码打包备份一下;
- 进入代码根目录,执行
git init; -
创建编写.gitignore文件,因为一些非代码文件,如图片、视频等,是不需要进入版本控制的,应告诉git忽略。注意:已进入版本控制的文件,即使在.gitignore里列出,git也不会忽略的。 由于文件比较多,目录结构比较复杂,所以可能很难一次性找到所有需要过滤的文件,可以先
git add *,然后通过git status来查看哪些文件已被加入暂存区,如果有需要过滤的文件被加入了暂存区,则执行git reset取消 暂存区内容,再次编辑.gitignore; -
确认需要过滤的文件都能被.gitignore中的内容匹配后执行
git add * && git commit -m "init"; -
将本地的git版本库与Gitlab服务器端的git版本库关联起来。假设Gitlab服务器端版本库的http链接为http://gitlab.server.com/xxx.git,执行
git remote add origin http://gitlab.server.com/xxx.git; -
将本地版本库代码推送到远程Gitlab服务器端。执行
git push origin master。
这样,生产服务器上的代码就迁入版本控制了,之后代码部署,只需从Git远程服务器拉取(pull)一下就可以了。
代码部署过程,原本也想通过hook方式---在代码提交进入master分支时,触发hook脚本,将master分支最新的代码拉取到生产服务器上,但一方面由于网络设定---测试服务器不能主动连接生产服务器,
另一方面谨慎起见,没有采用这种自动方式。在代码提交到Gitlab服务器端后,需要登录到生产服务器执行git pull。
项目/代码文档
入职一段时间后,虽然为运营平台写了几个功能模块,但对于与这几个模块关联的其他模块的实现逻辑并不清楚。对于非我实现的模块具体要解决的问题、以及各个模块的数据来源等也不清楚,也没有文档可查阅,所以着手写一份代码文档---
- 说明各个功能模块解决的问题、实现逻辑、API、相关cron脚本、数据表;
- 说明运营平台的请求处理过程、用户身份认证方式;
- 前端页面的构成(因为该运营平台所有页面统一使用一种iframe组合的结构);
- 指出代码中一些隐藏的bug、代码中的“坏味道”,并针对代码存在的问题,提出一些编程建议;
对于前端页面HTML、CSS、JS,我没有过多纠结。我们前端方面的技能不咋地,前端实现依赖于BootStrap、jQuery等开源代码库。
这项工作花费的较多时间,导致到后来有点赶工作,文档也写得比较粗糙。现在来看,这份文档写得很不好,只有文字叙述,没有图表,比较枯燥,当然部分原因也是该运营平台没有采用一个完整的框架,各个模块通过前端页面拼凑起来。
该文档中提出的一些编程建议却有一些可取之处:
1.
代码上线之前,务必先删除调试语句,比如common.php中的:
file_put_contents('/tmp/cron_test_ip.txt', print_r($ip, true));
调试语句对于正式上线的代码来说是多余的,会影响应用的性能,也可能带来安全问题。
2. 清楚地理解你写下的每行代码。
对于非函数式语言来说,每行代码都可能有一些“副作用”,如果你没有理解好你写的代码,就可能带来你无法预料的后果,也会花费你大量调试时间,所以不要轻易使用你还不是很理解的函数、类以及语言特性。
3. 一份代码“写三遍”。
编程是一个将大脑中的想法转化为可执行程序的过程,如果想法还不清楚,也就不可能写出正确的程序,即使写出的程序可执行,也可能会存在逻辑上的漏洞,成为隐藏的bug。写程序也并不是一气呵成的,而是一个反复编写调试的过程,这个过程非常关注细节,可能导致你无法从整体上把握程序的结构、性能等问题,所以在写完一个程序,程序也能执行了,你还得重新阅读思考一遍你写的程序。
第一遍:仔细思考要用程序来实现的任务逻辑,避免逻辑错误、漏洞;
第二遍:编写程序,旨在实现一个可执行的程序;
第三遍:重新完整地阅读一遍程序,去除不必要的语句,优化代码结构,提高程序性能。
4. 恰当处理cron脚本/API文件。
应将cron脚本/API文件放在恰当的目录下,在cron脚本/API文件数目较多时,应使用较为细分的目录结构对cron脚本/API文件进行归类。另外,应及时清除弃用的代码文件。
5. 前端页面代码尽可能分离HTML、CSS、JS。
务必不要内联引用CSS,即不要通过使用HTML标签的style属性来为标签添加CSS效果,因为这会造成大量的冗余代码,并且影响了HTML代码的简洁。
最好是将HTML、CSS、JS代码分离成不同的文件,即使用外部引用JS、CSS。优点有3:1)提高HTML、JS、CSS代码各自的简洁易读性;2)能够在多个页面(甚至整个网站)之间共享JS、CSS,提高代码复用,减轻代码更新的工作量,提高网站风格的一致性;3)方便网站内容动静分离,分别对JS、CSS代码进行压缩处理,也能使用CDN来加速请求响应。
退一步,也可以在HTML的<style>、<script>标签中编写CSS、JS代码。
6. DRY(Don't Repeat Yourself)。
不要复制粘贴代码。在发现相同代码在不同地方出现两次以上时,就应使用函数、类、公共文件等方式来避免重复代码的出现,提高代码的复用性,也为未来更新代码减少工作量。
7. 尽可能避免使用依赖特定操作系统、文件系统的操作。
例如:
(1)尽可能避免通过绝对路径引入文件,因为当代码中出现大量绝对路径时,代码迁移或变更的工作量就会大得多,而且可能会遗漏更改,从而导致bug。可以通过在一个公共文件中为项目根目录定义常量,在需要时基于该常量来引入文件,代码迁移或变更时只需更改该变量的值就可以了。另外,如果可行,则尽可能使用相对路径。
(2)尽可能避免直接调用操作系统提供的shell命令来完成任务。一方面某些特殊符号对于shell来说是有特殊意义的,如果参数中带有这些特殊符号就需要特别注意;另一方面对于代码的可移植性来说,直接调用shell命令是很大的问题。一般来说,编程语言都有一些库来支持对文件系统等对象的操作,应尽可能使用这些库来完成任务。
规范宣导
为了推行规范,需要和组内运营开发同事说明规范的必要性、如何执行规范(如Git的使用、Git工作流)、哪些东西可以从代码文档中查询等,所以简单了做了个分享,ppt见:规范化运营开发。
如何推行“定期code review”
You know, i am a newcomer,在工作中很难让同事们定期花点时间坐下来review代码,so,我只好实现一个自动化工具---一个cron脚本,每周执行一次,获取一周以来的commit,为其中每个committer随机分配另一个committer一周以来的所有commit作为review任务,将任务中的commit在gitlab上的超链接发送到各自的邮箱。
代码中导入的TofApi是我对公司提供的统一消息发送接口的Python封装。
如何推行“编码规范”
与“如何推行‘定期code review’”一样,我也是编写了一个自动化小工具来帮助推行编码规范---一个cron脚本,先定制git log命令参数,脚本中调用该git log命令,解析出需要的数据,对不同类型的代码文件使用不同的静态分析程序来分析每行代码不符合编码风格之处,然后将结果提交到gitlab的一个特定代码库中,并将结果的超链接发送到每个代码文件相关人员(对该文件做过增删的人)的邮箱,以提供编码风格改进参考。
该工具目前支持js、php、python文件代码的分析:
- js代码的分析是以Google JavaScript Style Guide为标准,借助Google的closure_linter工具进行分析(我对该工具的代码进行了hack,以支持过滤正则表达式文件名表示的文件)
- php代码的分析是以Zend Coding Standards(http://framework.zend.com/wiki/display/ZFDEV2/Coding+Standards) 为标准,借助phpcs进行分析
- python代码的分析是以PEP 8为标准,借助flake8进行分析
主代码见:codelintset.go。
由于最近对golang比较感兴趣,所以主程序使用golang实现。
代码中涉及的send_mail.py也是使用上面提到的TofApi的一个邮件发送脚本,template.tmpl是一个golang模板,用于生成静态分析结果,包括源码、分析结果、相关人员三个部分。
注意:
这个程序还有点问题 --- git在每个commit中会记录两个时间:author date(文件增删改的时间)和committer date(commit的时间),但很有可能某个变更在commit到本地版本库后,过了很长时间才push到远程服务器。
该程序是在gitlab服务器上每天执行一次,其中git log的参数--since是对committer date起作用。即使一天之内有新commit push到gitlab服务器,该程序执行定制的git log命令,结果也很可能为空,因为是commit一天之后才push的。
查了一下gitlab的API,好像也没找到commit push的时间的API,估计得自己去分析gitlab的数据库,然后读取commit push的时间。
2013-10-22 更新
codelintset.go已更新为第二版,通过读取gitlab数据库中的相关数据来解决上述问题,并将原来需要配置的常量全部放到json文件,程序运行时会解析该json文件。这样,修改配置不需要重新编译源码。