前段时间,工作中遭遇一次故障,虽然不算什么“疑难杂症”,倒也花了不少时间才真正找到故障的原因,故也值得记录一下。
为方便读者快速理解故障,先给出系统大致的架构图:
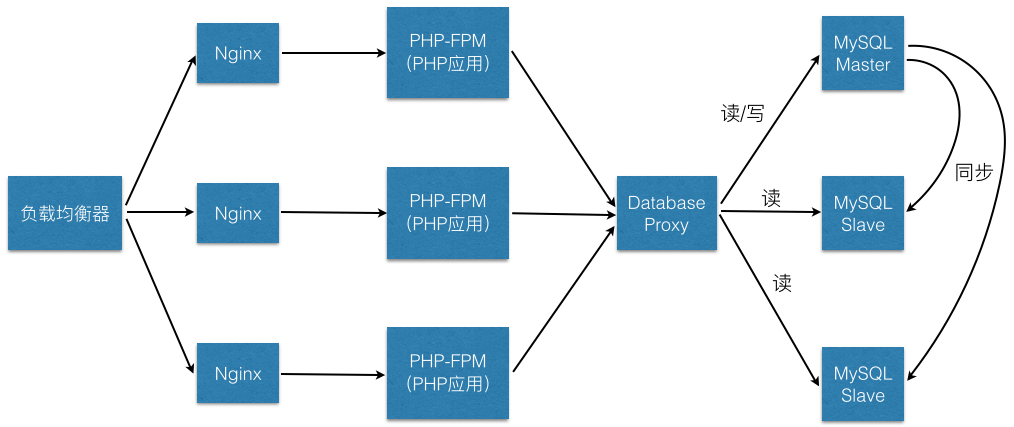
其中,
- 每台Web服务器上开启12个PHP-FPM实例,并配置到Nginx的upstream,每个实例最多可以开启10个子进程
- “Database Proxy”的代理规则为:写操作及事务中的所有SQL操作都交给主MySQL处理,其余的读操作都交给任意一台从MySQL处理
故障所表现的现象包括:
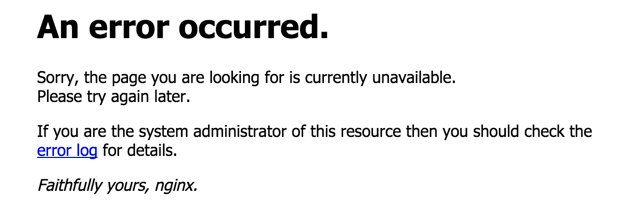
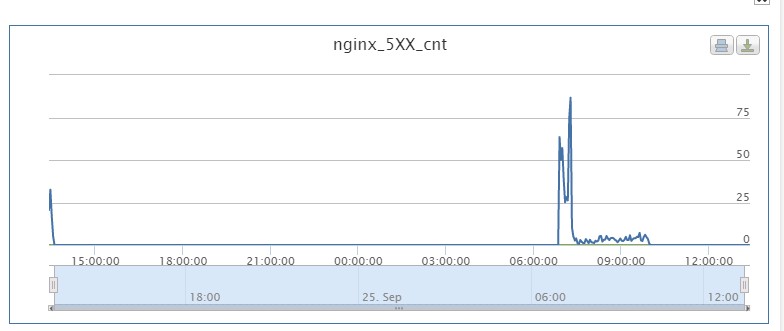
1.大量请求响应为502,但每次故障发生时,错误响应一般集中在一台Web服务器,如下图所示:
2.(一台或多台)MySQL数据库服务器CPU使用率飙升(但并非总是一起表现故障),如下图所示:
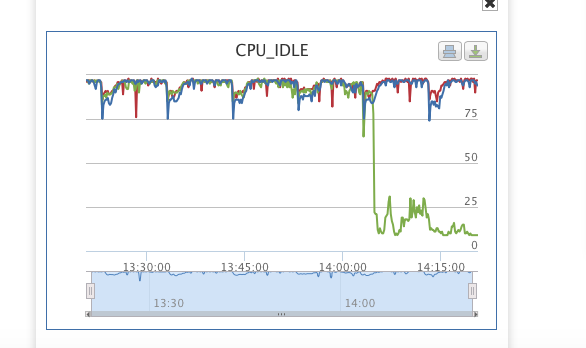
故障刚开始出现时,重启/关闭出现故障现象的MySQL服务,或将出现故障的Web服务器上所有PHP-FPM重启,也能解一时的问题,但治不了本,故障还是频繁出现。
在故障发生时,从相关服务器上收集到的信息如下所示:
1.出现故障现象的Web服务器 - CPU使用率、内存使用率等系统指标均正常,但PHP-FPM子进程数达到上限(12 x 10 = 120),并且PHP-FPM进程与数据库代理服务器之间的网络连接数量较多(与PHP-FPM子进程数大致相当)
2.出现故障现象的MySQL服务器 - CPU使用率飙升,主要为MySQL进程占用;MySQL进程与数据库代理服务器之间的网络连接较多
3.继而,对出现故障现象的MySQL服务器上的数据库执行命令SHOW PROCESSLIST(查看当前MySQL实例运行着哪些线程),结果如下所示(截图只是一部分结果):
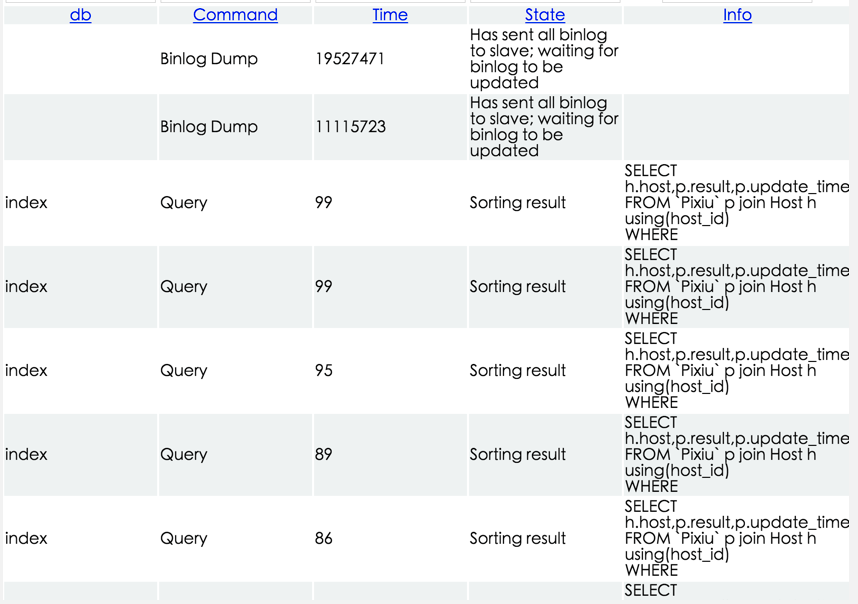
先来分析一下SHOW PROCESSLIST的执行结果:
Command字段,表示当前线程正在执行的任务类型
db字段,表示当前线程所执行任务涉及的数据库是哪个
State字段,表示当前线程所处的状态
Time字段,表示当前线程处于State字段持续的时间,单位为秒
Info字段,表示如果当前线程是在执行查询操作(Query),那么查询的语句是什么样的,如非查询操作,则该字段为NULL
结果中,有两种任务线程:“Binlog Dump”和“Query”,其中“Query”数量占绝大多数(和MySQL进程与数据库代理服务器之间的网络连接数大致相当):
- Binlog Dump:该任务线程表明当前MySQL实例为主MySQL,并且其状态表明主从同步已顺利完成
- Query:表明当前线程正在执行一次SQL查询操作。该SQL为
SELECT h.host, p.result, p.update_time FROM PIXIU p join Host h using(host_id) WHERE ...,线程所处状态为“Sorting result”(正在创建排序索引),持续时间为86-99秒左右。很明显,这句SQL语句花费的时间过长,存在问题。
综合上面所述,可以引出一个猜测:由于这条SQL查询需耗费较长时间,并且被频繁执行,涉及该SQL的请求需要较长时间完成,大量SQL线程排队无响应,阻塞了大量PHP-FPM进程,在某些时候会达到PHP-FPM并发子进程数上限(更何况某个会被频繁访问的页面请求涉及该SQL,导致情况更糟),PHP-FPM无法处理新的请求,对于已有的请求也会因为超时导致Nginx响应502。
那么针对该猜测,可以做两个优化来解决故障:
- 优化这条SQL
- 使用缓存
这条SQL的完整语句为: SELECT h.host,p.result,p.update_time FROM Pixiu p join Host h using(host_id) WHERE result!='[]' order by update_time desc ,其中字段p.result的类型为 mediumtext NOT NULL ,字段p.update_time的类型为 timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP 。
由于业务逻辑并不要求该SQL的结果是排序的,所以我们将该SQL中的排序条件order by update_time desc删除,经测试发现查询时间大幅度降低到9ms左右(原来的平均查询时间为600多-700ms左右),另外,由于业务逻辑对于该条SQL涉及的数据的实时性要求不高,我们使用Memcached缓存了该SQL的查询结果。
重新部署,压测,并线上运行观察,之后故障再未发生。事后回想,故障也确实是在涉及该SQL的功能模块上线之后才发生的。