背景
工作中,我负责的系统是一个数据流处理服务 - 以流水线(pipeline)的形式分多级异步处理:

其中的 队列 实际使用的是 Disruptor,多生产者单消费者模式:
ThreadFactory factory = new ThreadFactoryBuilder().setNameFormat(name).setDaemon(true).build();
Disruptor<Event<T>> disruptor = new Disruptor<>(Event<T>::new, bufferSize, factory, ProducerType.MULTI, new SleepingWaitStrategy());
disruptor.handleEventsWith((Event<T> event, long sequence, boolean endOfBatch) -> {
consumer.accept(event.value, endOfBatch);
event.value = null;
});
服务运行在 k8s 集群上,每个容器节点上可能会运行多个 pipeline,也即意味着单个节点上会存在多个 disruptor 实例。
现象
近期突然收到测试环境很多节点(生产环境也有少量节点)的 CPU 使用率告警 - CPU 使用率持续 5 分钟以上超过 90%,如下其中一个任务节点的 CPU 使用率监控图:
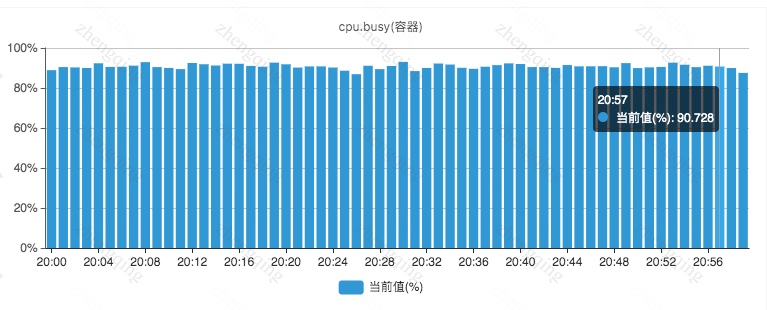

cpu.busy = cpu.system + cpu.user + 软/硬中断
注意其中 cpu.system 比 cpu.user 高不少,cpu.busy 又比 cpu.system 高不少。也即 CPU 时间片资源主要消耗在 内核态 和中断逻辑上(对于这些任务而言 cpu.user 指标也是异常的)。
这些节点运行的任务,几乎没有数据需要处理,也就是说几乎是空跑的。从线程数量监控以及 jstack 输出的堆栈跟踪信息,也未发现明显异常。
原因排查
将测试环境的任务在本地环境运行起来,并基于 How to profile JVM applications 一文中提到的火焰图工具,产出对应 JVM 应用的火焰图:
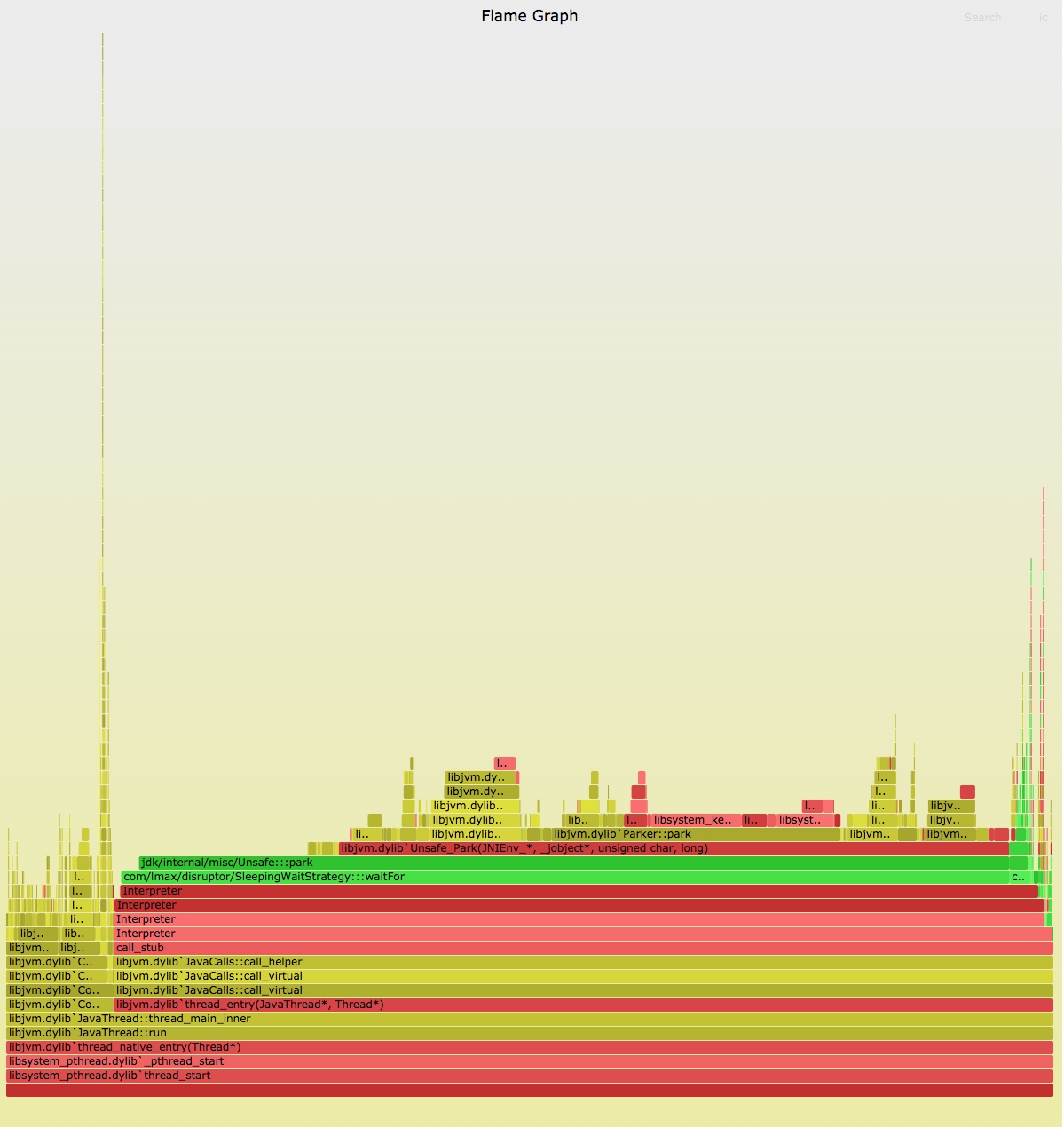
从图中可以大致看出其中 com/lmax/disruptor/SleepingWaitStrategy:::waitFor / jdk/internal/misc/Unsafe:::park 比较可疑,在调用栈中耗时最长。
从项目源码和 jstack 输出的堆栈跟踪信息可以看到,测试任务中大致涉及 18个 disruptor 实例,均使用 SleepingWaitStrategy 等待策略,该策略的 waitFor 方法实现如下所示:
public long waitFor(final long sequence, Sequence cursor, final Sequence dependentSequence, final SequenceBarrier barrier) throws AlertException {
long availableSequence;
// 默认 200
int counter = retries;
while ((availableSequence = dependentSequence.get()) < sequence) {
counter = applyWaitMethod(barrier, counter);
}
return availableSequence;
}
waitFor 方法中核心调用了 applyWaitMethod :
private int applyWaitMethod(final SequenceBarrier barrier, int counter) throws AlertException {
barrier.checkAlert();
if (counter > 100)
{
--counter;
}
else if (counter > 0)
{
--counter;
Thread.yield();
}
else
{
// sleepTimeNs 默认 100
// 间接调用 jdk/internal/misc/Unsafe:::park 方法
LockSupport.parkNanos(sleepTimeNs);
}
return counter;
}
LockSupport.parkNanos 方法的作用简单而言即让当前线程睡眠 sleepTimeNs 纳秒。
Disruptor 作为一个任务队列,自带一个线程池,线程池的线程工厂即构造方法传入的 factory,线程数量等于 disruptor.handleEventsWith 调用时传入的回调方法数量,handleEventsWith 的参数数量不定(public final EventHandlerGroup<T> handleEventsWith(final EventHandler<? super T>... handlers))。
18个 Disruptor 实例,每个实例有一个消费者线程,消费者线程不断检查队列中是否有新的 Event<T> 任务需要处理,如果有,则调用 EventHandler 回调方法进行处理,否则睡眠 sleepTimeNs 纳秒。
到此,结合监控指标,可以大致猜测:由于 sleepTimeNs 较小,导致多个线程的状态不断在 运行、睡眠、等待调度 之间切换,线程上下文切换非常频繁。
围绕 LockSupport.parkNanos 编写一个测试程序,来复现这个问题:
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.locks.LockSupport;
public class Test {
public static void main(String[] args) throws InterruptedException {
ExecutorService tp = Executors.newFixedThreadPool(18);
for (int idx = 0; idx < 18; idx++) {
tp.submit(() -> {
while (true) {
LockSupport.parkNanos(100);
}
});
}
CountDownLatch wg = new CountDownLatch(1);
wg.await();
}
}
在 3.2 GHz 6-Core Intel Core i7 配置 macOS 系统中,这个测试程序可以稳定地将 CPU 使用率控制在 700%+,如下 top -pid [测试程序的进程 id] 命令的输出:

其中 CSW 为线程上下文切换的次数。
既然问题原因在于多个线程频繁睡眠导致,那么解决方案也比较简单:
- 使用更大的值来替换 sleepTimeNs 默认值:
new Disruptor<>(Event<T>::new, bufferSize, factory, ProducerType.MULTI, new SleepingWaitStrategy(200, 1000 * 1000 / 10)); // 0.1 ms - 使用其他等待策略(WaitStrategy),比如:
com.lmax.disruptor.BlockingWaitStrategy
不过解决方案也有微小的负作用 - 部分新任务/Event<T>实例的处理时延会增大,但在我们的数据流处理场景下,这点时延增大对业务完全没有影响。
不过,这个问题应该是一直存在,为什么近期才收到告警,为什么以前从监控上未发现?
- 为什么近期才收到告警?因为这个监控告警是近期公司监控平台才统一配置的
- 为什么以前从监控上未发现?因为公司切换了新的监控平台,老的监控平台没有 cpu.busy 这个指标,而这些没什么数据要处理的任务长时间不需要开发维护,也就未得到及时关注。
扩展资料
- 上下文切换耗时多少?How long does it take to make a context switch?
LockSupport.parkNanos(100)真的就是睡眠 100 纳秒吗?LockSupport.parkNanos() Under the Hood and the Curious Case of Parking