设计一种存储,第一要明确应用场景和存储系统的工作负载,第二要了解底层硬件的特点。
1、Are You Sure You Want to Use MMAP in Your Database Management System?
MMAP(Memory-mapped file I/O)是操作系统提供的一种功能特性 - 将二级存储(磁盘、SSD)上一个文件的内容映射到程序/进程的地址空间,然后程序就可以以指针访问内存页的方式来访问文件内容。当程序访问到某个内存页时,操作系统就会自动将对应文件内容加载到该内存页中,当内存用满了,也会自动剔除某些内存页。
MMAP 其实就一个现成的缓冲池(buffer pool),核心特点就是简单易用,不需要重复开发,缺点是在需要时无法精确控制其行为。
使用 MMAP 的优势是由操作系统封装了如下功能:
- 从磁盘读数据
- 不同线程读相同数据的并发处理
- 缓存和缓冲管理(Caching and buffer management)
- 从内存中剔除/驱逐内存页
- 同一个机器上不同进程之间可以友好交互 🤔
- 跟踪脏页以及将脏页写入磁盘 🤔
- 相比 read/write 系统调用,mmap 不需要将内存页从内核空间拷贝到用户空间,而是直接从操作系统的内存页缓存中直接访问内存页,有一定的性能优势
MMAP 相关 POSIX API:mmap、madvise、mlock、msync。
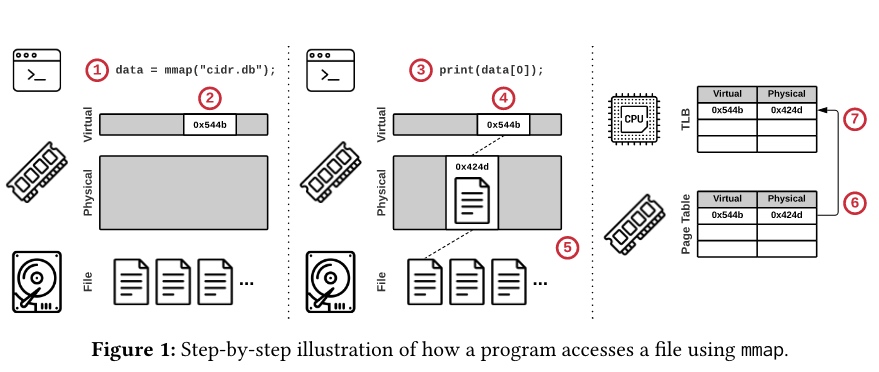
① A program calls mmap and receives a pointer to the memory-mapped file contents.
② The OS reserves part of the program’s virtual address space but does not load any part of the file.
③ The program accesses the file’s contents using the pointer.
④ The OS attempts to retrieve the page.
⑤ Since no valid mapping exists for the specified virtual address, the OS triggers a page fault to load the referenced part of the file from secondary storage into a physical memory page.
⑥ The OS adds an entry to the page table that maps the virtual address to the new physical address.
⑦ The initiating CPU core also caches this entry in its local translation lookaside buffer (TLB) to accelerate future accesses.
不过论文作者认为 mmap 存在一些数据安全性和系统性性能问题,为解决这些问题而引入的工程成本会抵消掉简单性:
1、事务安全性(Transactional Safety):由于透明的页式调度机制,操作系统可能会任意时刻将一个脏页刷到二级存储中,不管写事务是否已提交。DBMS 无法组织这种内存数据刷出,并且发生时也不会接收到任何信号。所以基于 mmap 的数据库系统只能采用复杂的协议来确保(写/更新)事务安全,手段上大概分3种:操作系统写时复制、用户空间写时复制、影子页管理(shadow paging)
2、I/O 停顿(I/O Stalls):
- mmap 不支持异步读;自己搞缓冲池的话,可以使用异步 I/O(比如 libaio、io_uring)来避免查询时阻塞线程
- 对于 mmap,因为操作系统会自动/透明地剔除一些内存页,这样可能导致 - 如果某些只读查询命中了已被剔除的内存页,就会无法预知地触发阻塞性的页错误/缺页处理
解决方案:1、使用 mlock,不过操作系统对一个进程能锁住的内存页数量有限制;2、使用 madvise 的 MADV_SEQUENTIAL 标记,仅能问题的一部分;3、使用额外的线程来进行内存页预取,避免主线程被阻塞,不过会引入较大的复杂性
3、错误处理:
DBMS 的核心职责之一是确保数据完整性 - 比如:校验磁盘数据是否有损坏
- 使用 mmap,DBMS 需要在每次内存页访问时检查校验和(checksum),因为内存页一次访问之后操作系统可能会将该页驱逐到磁盘
- 如果 DBMS 是使用非内存安全的编程语言编写的,就有可能在指针操作时损坏内存页内容,所以需要在内存页刷到二级存储之前进行错误检测,mmap 会默默地将损坏的内存页持久化到二级存储
- 使用 mmap 也更难优雅地进行 I/O 错误处理,和 mmap 内存交互的任何代码都可能抛出 SIGBUS 信号,DBMS 必须使用信号处理器(signal handlers)来处理 ❓
4、性能问题(最重大):
- 大家普遍认为 mmap 性能优于传统文件 I/O(read/write),因为它避免两个开销:(1) 显式调用 read/write 系统调用的开销 (2) mmap 会返回指向操作系统页缓存的页指针,因此避免了到用户内存空间的一次内存拷贝,也因此降低了内存占用;由此,大家也认为在 SSD 上 mmap 的性能优势会进一步扩大。
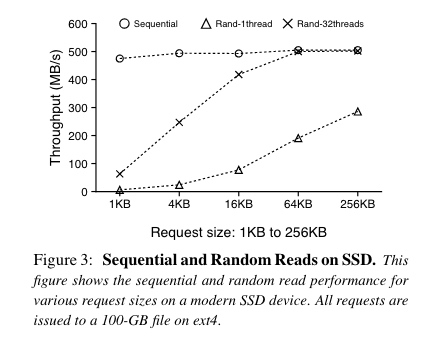
- 不过实验测试发现:对于高带宽的二级存储设备(比如 SSD),DBMS 管理的数据量大于内存空间时,操作系统的页驱逐机制(page eviction mechanisms)多线程扩展性比较差(备注:因为 SSD I/O 带宽大、访问速度快,页驱逐机制就可能成了瓶颈)(we have found that the OS’s page eviction mechanisms cannot scale beyond a few threads for larger-thanmemory DBMS workloads on high-bandwidth secondary storage devices. We believe that one of the main reasons these performance issues have gone largely unnoticed is due to historically limited file I/O bandwidth)。瓶颈源于3个因素:
- 页表争用(page table contention)/ 锁(备注:当前 linux 内核实现优化了这个问题,linux/split_page_table_lock.rst at master · torvalds/linux (github.com))
- 单线程页驱逐(single-threaded page eviction),Page Cache eviction and page reclaim | Viacheslav Biriukov
- 旁路转换缓冲击落(TLB shootdowns):TLB shootdowns occur during page eviction when a core needs to invalidate mappings in a remote TLB. Whereas flushing the local TLB is inexpensive, issuing interprocessor interrupts to synchronize remote TLBs can take thousands of cycles
实验分析:
As a baseline, we used the fio storage benchmarking tool (v3.25) with direct I/O (O_DIRECT) to bypass the OS page cache. Our analysis focused exclusively on read-only workloads, which represent the best-case scenario for mmap-based DBMSs.
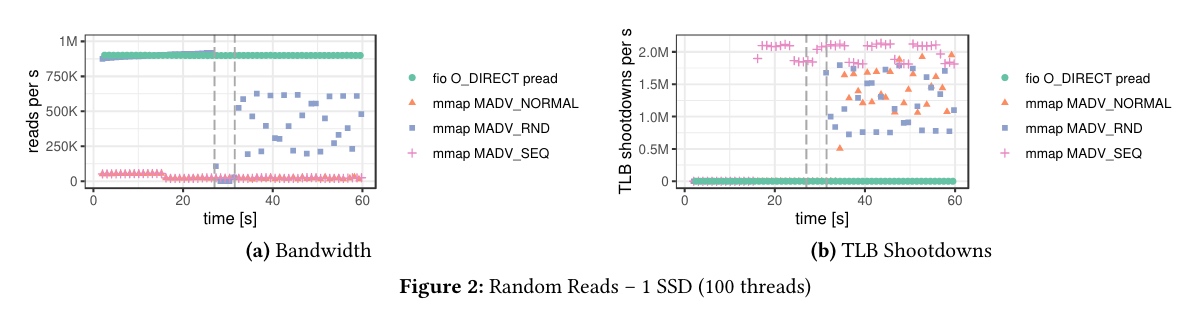
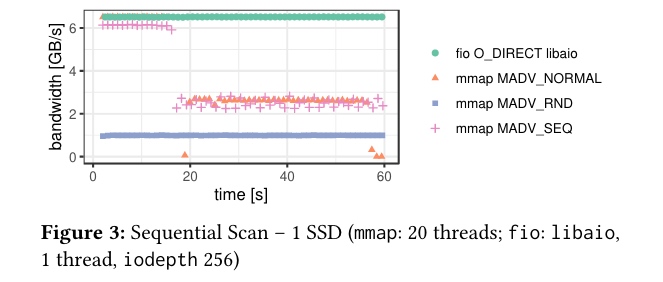

那么,到底要不要使用 mmap 呢?直接使用 ssd?还是自己搞一个 buffer pool?
论文作者给出这样的结论:
- 以下情况不要使用 mmap:
- 需要以事务安全的方式进行更新操作
- 希望处理缺页错误时不会阻塞在慢 I/O 上,或者希望明确控制哪些数据应该在内存中
- 关心错误处理,也希望始终返回正确的数据结果
- 要求在快速持久化存储设备(比如 SSD)上获得高吞吐
- 以下情况可能应该使用 mmap:
- 内存可以容纳整个数据工作集(或者说整个数据库),并且是只读的工作负载
- 希望将一个产品快速推向市场,也不关注数据一致性或者长期的工程技术债
- Otherwise, never 🤣🙃
彩蛋:论文的奇数页页眉 😂
2、re: Are You Sure You Want to Use MMAP in Your Database Management System?
本文作者认为自己实现一个内存分页管理器/缓冲池比较复杂,使用 mmap 来实现存储系统会很快。
不过吐槽了原论文没有给出可供选择的替代方案,基准测试和结论之间也没太多相关性(compares apples to camels),也低估了自己实现一个替代 mmap 的缓冲池的复杂性。
不用 mmap 的话,论文提及的那些问题,也是要解决的(If you aren’t using mmap, on the other hand, you still need to handle all those issues. That is a key point that I believe isn’t addressed in the paper. Solving those issues properly (and efficiently) is a seriously challenging task. Given that you are building a specialized solution, you can probably do better than the generic mmap, but it will absolutely have a cost. That cost is both in terms of runtime overhead as well as increased development time.)。
原论文的实验说明了 mmap 的性能问题,但是换个 buffer pool 的实现能不能获得更好的性能呢?该文作者持悲观态度。
存储系统实际面对的工作负载不会是完全的随机读(写)或顺序扫描,通常都具有一定的热点数据,这时 buffer pool 的优势就会体现出来?
- 关于“问题 1 - 事务安全性” - 不用 mmap,解决这个问题的方案没什么不同(I don’t actually care if the data is written to memory behind my back. What I care about is MVCC (a totally separate concern than buffer management). The fact that I’m copying the modified data to the side means that I Can support concurrent transactions with far greater ease.)
- 关于“问题 2 - I/O 停顿” - 该文作者认为确实个问题(not having control over the I/O means that you may incur a page fault at any time),并且是基于 mmap 的系统要面对的最大问题。不过实际情况是 linux 系统中 io_uring 之外的异步 I/O 方案在某些时候异步操作也会是阻塞的。是否使用 mmap,这个问题的解决方案也没有本质区别。
- 关于“问题 3 - 错误处理” - 该文作者以自己开发的 Voron 为例说明即使使用 mmap,也可以较好地实现校验和检查(使用一个 bitmap 来记录哪些内存页被访问过,在第一次访问某个内存页的时候检查校验和),并认为程序一次运行过程中对于指定的一个内存页检查一次就可以,其他情况下的检查都是没有意义的。When you use read() to get data from the disk, you have no guarantees that the data wasn’t fetched from a cache along the way. So you may validate the data you read is “correct”, while the on disk representation is broken. For that reason, we only do the check once, instead of each time. 🤔 好像不是这个理?
- 至于发现 I/O 错误,如何处理?该文作者认为答案只有一个 - 让它崩溃然后重新恢复并运行(Crash and then run recovery from scratch),因为如果 I/O 系统返回了一个错误,应用逻辑也不会有任何方式知道 I/O 系统的当前状态是什么,应该怎么解决,唯一的方式就是停下来,重新加载一切(应用 WAL 进行恢复),回到一个稳定状态。
- 关于“问题 4 - 性能问题” -
- 页表争用(page table contention):linux 内核已优化解决
- 单线程页驱逐(single-threaded page eviction):如果写/更新频率不高,脏页不多的话,也不会成为性能瓶颈
- 旁路转换缓冲击落(TLB shootdowns):在一定条件下才会成为性能瓶颈,当你真的遇到时应该也会多花钱买内存来解决 🤣🙃(In order to actually observe the cost of TLS Shootdown in a significant manner, you need to have: (1) really fast I/O (2)working set that significantly exceeds memory (3) no other work that needs to be done for processing a request; In practice, if you have really fast I/O, you spent money on that, you’ll more likely get more RAM as well. And you typically need to do something with the data you read, which means that you won’t notice the TLB shootdown as much)
3、WiscKey: Separating Keys from Values in SSD-Conscious Storage / Introducing Badger: A fast key-value store written purely in Go
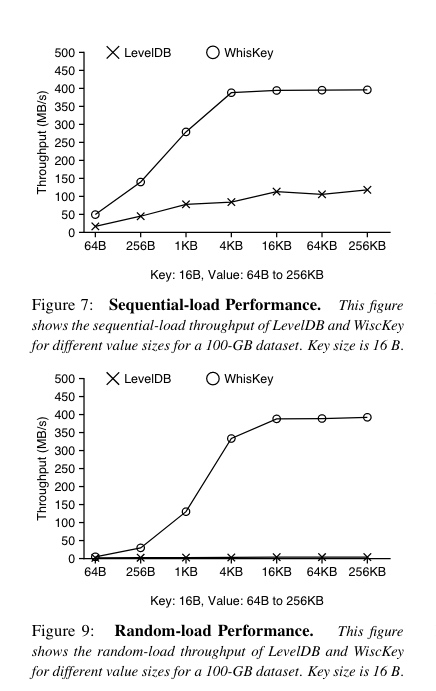
WiscKey 是一个基于 LSM (Log Structured Merge)树的 KV 存储引擎,针对 SSD 的随机读和顺序读性能特点,将 Key 和 Value 分开存储,以尽可能缩小 I/O 放大问题,提升性能。
Value 存放在 Log 文件中,LSM 树仅存储 Key 和 Value 在 Log 文件的位置以及长度/大小。
对于 Value 比较大的应用场景,性能优势明显。
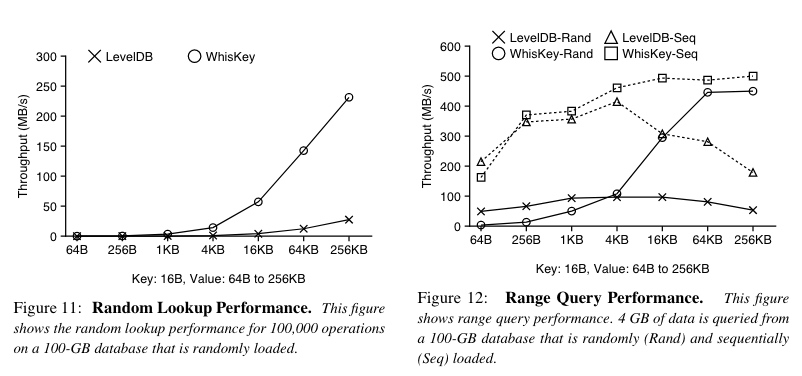
因为 LSM 树不存储 Value 本身,通常比较小,可以全部放在内存中,所以不考虑获取 Value 的值,点查和范围查找速度非常快。
LSM 树比较小,所以 Compaction 次数少,速度快(特别是如果整个 LSM 都放在内存中的话)。Compaction 过程中不需要读写 Value 的值,所以 I/O 放大倍数要小很多。
点查过程,从 LSM 树中获取 Value 的位置和大小后,需要从 Value Log 中获取 Value 值。因为 LSM 树小,所以读放大倍数小,综合起来看,WiscKey 点查的性能优势依旧明显。
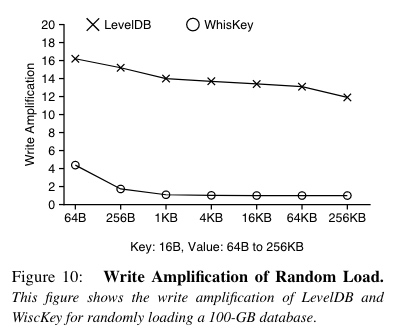
范围查找/遍历过程,先从 LSM 树中获得目标范围内的所有 Value 的位置和大小,放入队列,使用多线程进行并发预取,利用 SSD 随机读的吞吐能力随并发树近线性增长的特点。
Value Log 也需要 GC,清理掉无用的 Value 值。LSM 树的 Compaction 主要是为了提升查找/检索的性能/效率,控制读放大,减少内存/磁盘空间占用是次要的。Value Log 的 GC 则主要是为了减少内存/磁盘空间占用。
为了实现在线的轻量级 GC,Value Log 中也存储了 Key,

tail 指向 Value Log 有效值范围内时序上最先写入的那个 value 的位置。
head 指向 Value Log 中下一个新 value 写入的位置。
tail 和 head 及其对应的位置信息均作为 kv 存入 LSM 树中(head 的指向什么时候会更新?:每次有新值写入的时候都更新?还是在 GC 的过程中才会更新?)
GC 的流程为:
① 从 tail 指向的位置开始顺序扫描一块数据,根据其中的 key 检索 LSM 树,确认当前 value 是否有效(没有被删除也没有被覆盖)
② 如果有效则插入到 head 指向的位置,head 指向移动到下一个位置;如果无效,则直接丢弃
③ 一块数据处理完成后,移动 tail 指向到下一个位置,释放/回收原来数据块的存储空间;然后继续循环处理
疑问:1. GC 过程中每次向 head 插入有效值时,是否先要从 LSM 树中查询最新指向的位置?2. 在根据 key 从 LSM 树查询后将有效值写入 head 位置前,有新数据写入的话,怎么处理?GC 期间是否要停止正常的写操作?还是说对某个临界区加锁?
LSM 树原理:
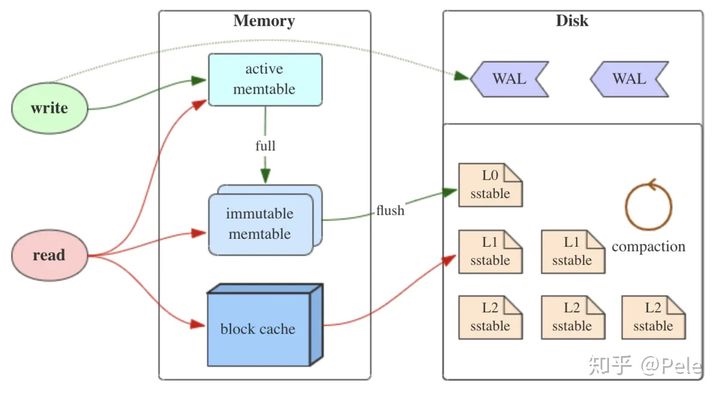
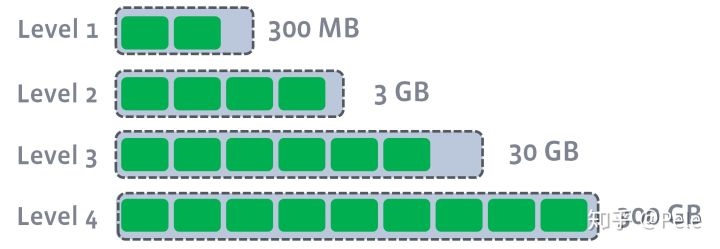
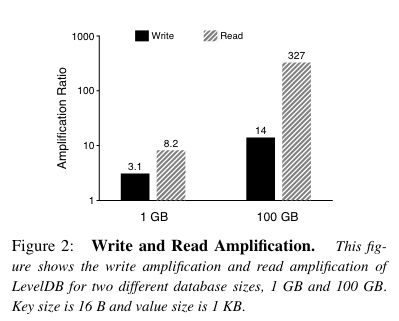
4、Toward a Better Understanding and Evaluation of Tree Structures on Flash SSDs(VLDB)
PTS - Persistent tree data structure
使用 LSM 树(RocksDB)和 B+ 树(WiredTiger)来分析 SSD 基准测试(Benchmarking)中可能踩到的 7 个坑(pitfall):
(1)Running short tests / 测试过于短平快 ⚡️
随着使用时间的增加,SSD 的性能会一定的动态变化。
Because both the PTS and SSD performance vary over time, short-lived tests are unable to capture how the systems will behave under a continuous(non-bursty)workload.
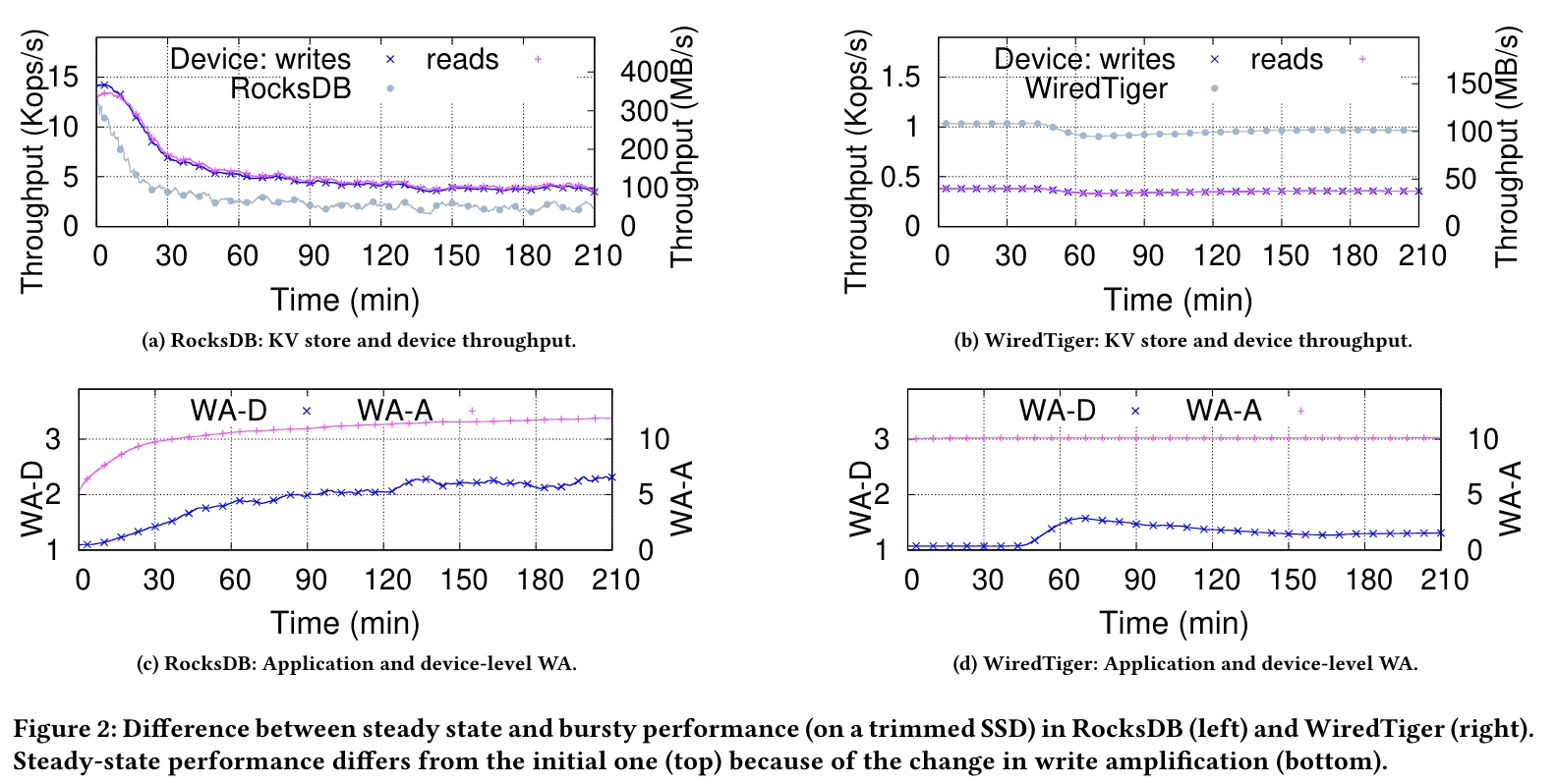
WA-A(应用/存储系统的写放大) increases over time while the levels of the LSM-Tree fills up, and its curve flattens once the layout of the LSM tree has stabilized.
WA-D(SSD 设备的写放大) increases over time because of the effect of garbage collection.
(2)Ignoring the device write amplification (WA-D) / 忽视了 SSD 设备本身的写放大 ⚡️
- WA-D directly affects the throughput of the device, which strongly correlates with the application-level throughput.
- WA-D is an essential measure of the I/O efficiency of a PTS. 端到端的写放大倍数应该是 WA-A 乘以 WA-D
- WA-D measures the flash-friendliness of a PTS.
- A low WA-D indicates that a PTS generates a write access that does not incur much garbage collection overhead in the SSD.
- 以前大家可能认为 LSM 树(顺序写)相比 B+ 树(随机写)对 SSD 更友好,但实测 WA-D 颠覆了这个认知
(3)Ignoring the internal state of the SSD / 忽视了 SSD 的初始内部状态 ⚡️
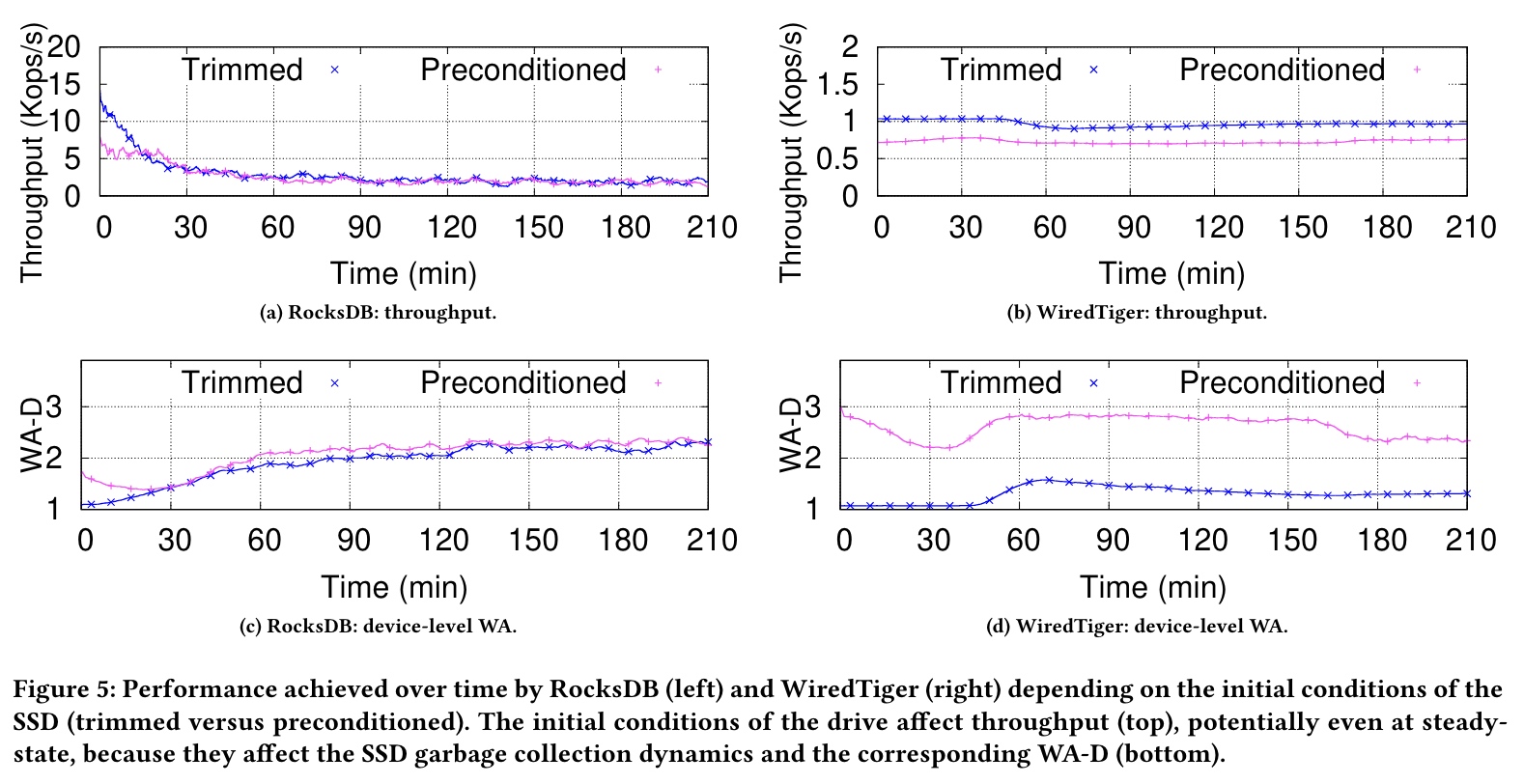
Trim(Discard)的出现主要是为了提高GC的效率以及减少写入放大的发生,最大作用是清空待删除的无效数据。在SSD执行读、擦、写步骤的时候,预先把擦除的步骤先做了,这样才能发挥出SSD的性能,通常SSD掉速很大一部分原因就是待删除的无效数据太多,每次写入的时候主控都要先做清空处理,所以性能受到了限制。
The steady-state performance of a PTS can greatly differ depending on the initial state of the drive, this is surprising.
This phenomenon is caused by how the LBA (logic block address) access patterns of RocksDB and WiredTiger intertwine with the SSD garbage collection mechanism as a function of the initial state the drive.
WiredTiger only writes to a limited portion of the logical block address space.
(4)Ignore the dataset size / 忽视了数据集大小
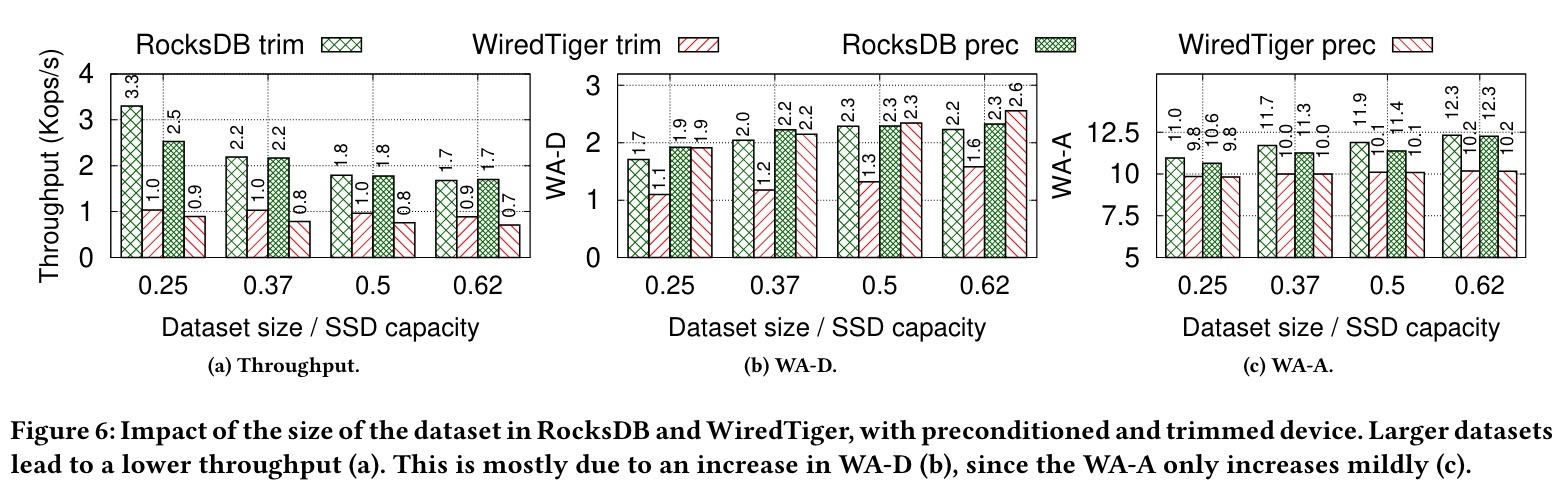
The amount of data stored by the SSD changes its behavior and affects overall performance.
The performance degradation brought by the larger dataset is primarily due to the idiosyncrasies(特质/特点) of the SSD: larger datasets lead to more valid pages in each flash block, which increases the amount of data being relocated upon performing garbage collection, i.e., the WA-D
(5)Ignoring the extra storage capacity a PTS needs to manage data and store additional meta-data / 未考虑空间放大(Space amplification)
涉及存储成本
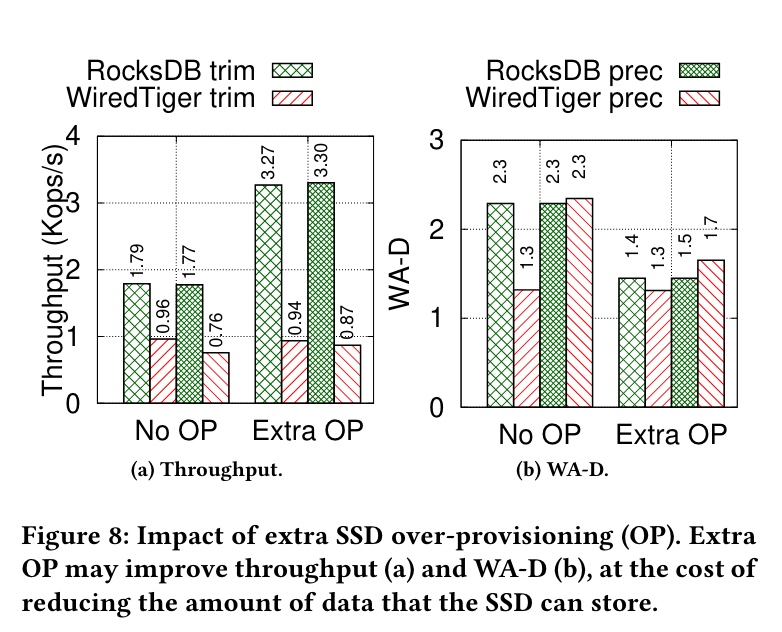
(6)Ignoring SSD over-provisioning
成本与性能之间的权衡折中 - 可以预留一部分 SSD 空间给 SSD 做 GC 使用,这部分空间对文件系统不可见。
(7)Ignoring the effect of the underlying storage technology on performance