上周五早上9点多,我还在上班的路上,接到技术leader的电话:线上突然出故障了;接着发来一张故障信息页面截图:

截图包含的信息是:数据库中没找到数据表Users。
但同事检查过数据库,Users数据表是存在的。
我快速地回忆了一下最近的代码发布和环境变更 - 前一天有个同事对线上机器做了点改动。因此,让同事赶紧检查一下之前的改动是否有问题,经检查确认改动没有问题,而且稍微思考一下就应该明白不是配置的问题,如果是配置的问题,那么问题应该早就出现了,而不是在早上9点多时候才发生。
我翻了翻手机中最近收到的几条告警短信,去除重复告警短信,只有两条告警:
- 某台Web服务器上出现大量的500错误
- 某台数据库服务器的磁盘使用率为98.99%
由此可以推测两个故障原因:
- 那台Web服务器上应用的数据库配置有问题 - 但检查之后确认没有问题
- 由于那台数据库服务器磁盘满导致的问题,虽然一时还想不到其中的关联 - 同事在检查之后,确认那台机器的磁盘确实已满,但通过内网的数据库管理后台,可以正常访问数据库,所以认为应该不是磁盘满导致的问题
如此,一时我也没想明白故障的原因。
接着,同事发来消息:只有登录用户才会遇到这个问题!
这时,基于之前的线索,基本能断定故障原因是 - 数据库服务器磁盘满。为什么呢?
- 数据库管理后台默认是只读:读数据表列表、数据表结构、单个表的若干条数据
- 我们应用在实现上有这样的逻辑:登录用户的每次访问需要登录权限的页面都会自动更新用户的最新的访问时间,即Users数据表的updated_time字段,也即会写Users数据表。
由于磁盘已满,所以写会失败,故障信息提示“数据库中找不到Users数据表”,估计和MySQL的写实现有关。
之后清理了磁盘,故障立即恢复。
我一直认为:排除故障/解决问题时,我们就像侦探一样 - 收集信息、思考信息之间的关联、透过现象看本质。故障现象很多时候会导致迷惑,如何能破除迷惑?- 全面地掌握系统的信息并作出思考。
但是,故障发生时,我们首先要考虑的是恢复故障,尽可能减小对SLA的影响。大多数时候,我们都暂时无法找到故障原因,而且“找到故障原因”并非是“故障恢复”的必要条件,所以故障发生时,不要只顾着查找原因,先看看如何恢复故障。比如:本文所述的这个故障,如果没有想明白原因,可以先把排查过程中发现的所有异常 - 磁盘满 - 都解决了。
再来说说这个故障的原因 - 磁盘满。个人认为这个故障原因是比较低级的,可见我们监控运维的缺失。为什么磁盘使用率到了98.88%才告警?大量占用磁盘的日志文件是否可以定期自动清理?后来,我们将磁盘告警的阈值修改为85%,并且定期删除一段时间之前的日志文件。
故障解决之后,我了解到数据库服务器上占用磁盘最多的竟然是数据库代理服务的日志。数据库代理服务会将每个网络请求的信息记录在日志中,在网络请求量大时,日志会快速增长 (这样的日志信息除了在故障发生时帮助排查故障,没有其他用处,完全可以定期清除) 。
那么数据库服务、数据库代理服务是如何部署的呢?前一篇文章给出了一张系统架构图,其中数据库代理服务和数据库服务我们运维的同学实际上是这样部署的:
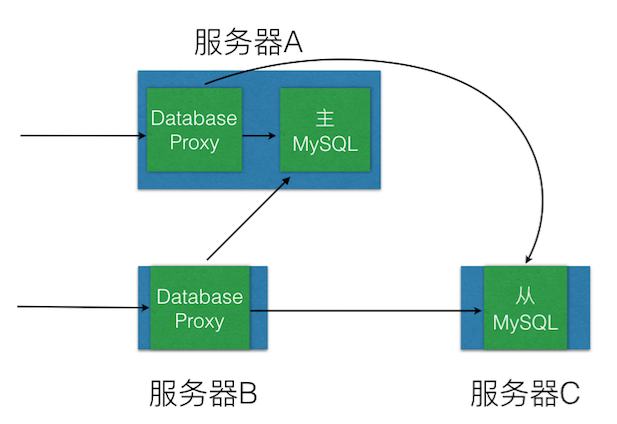
这样的部署徒增别人的迷惑,增大故障排除的难度,而且主MySQL与数据库代理服务之间会存在资源竞争,特别是在数据量访问量大的时候。
导致这种低级故障和部署混乱的原因又是什么呢?- 在我们团队中,运维同事是与另一个业务部门共享的,由于另一个业务部门做的是公司的重点业务,运维同事的KPI是根据它们业务来定,也就是说运维同事在我们这完全是友情支持,又能花多少时间来帮我们做运维呢?
(完)