问题
之前涉及的一项工作要求对某些数据做全文索引,并以API向其他内部系统提供搜索查询服务。
由于需要建全文索引的数据量并不大,且已有的数据都以 …
之前涉及的一项工作要求对某些数据做全文索引,并以API向其他内部系统提供搜索查询服务。
由于需要建全文索引的数据量并不大,且已有的数据都以 …
目前工作中开发流程还比较初级,甚至连测试服务器都没有,代码的变更都是直接先在开发人员的本地机器上简单测试 …
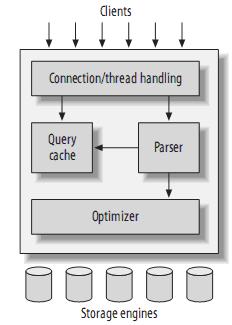
1. 每个客户连接在服务器进程中都拥有自己的线程,每个连接所属的查询都会在指定的某个单独线程中完成,这些线 …
Page 1 / 1